Use Cases¶
This chapter describes how to use Texta Toolkit’s different tools to answer some research questions.
How to search for a topic if you don’t know enough topic words?¶
Research question: What is the frequency of sport-related documents through time?”
Pre-requirements:
A project with the sputnik newspaper articles dataset is created.
This project is active (chosen on the upper panel in the right).
Train an embedding¶
Go to Models > Embeddings. Click on “CREATE” in the top-left. Create an Embedding (Fig. 144). Read more about the creating parameters here.
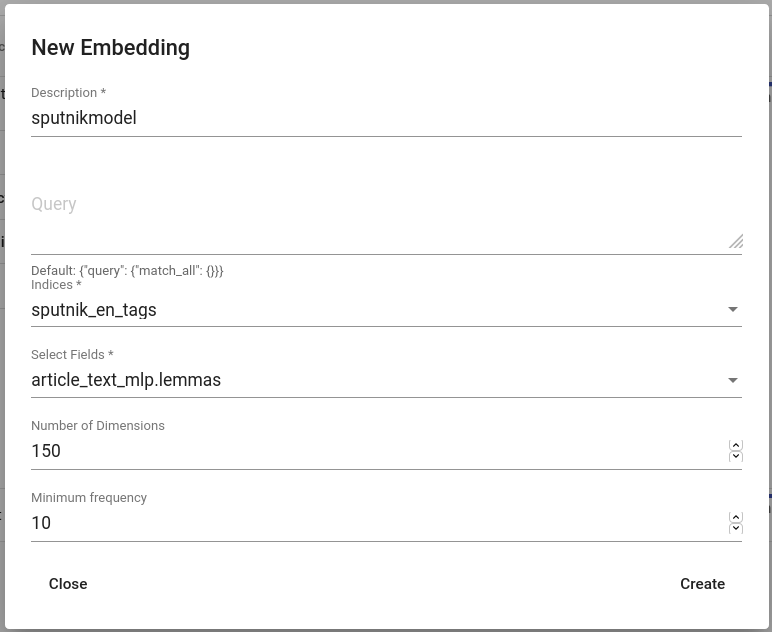
Fig. 144 Creating an embedding for sputnik¶
This step might take a while. After the embedding model is trained, the Lexicon Miner can be used.
Use Lexicon Miner¶
Use the Lexicon Miner for mining other words than just “sport”.
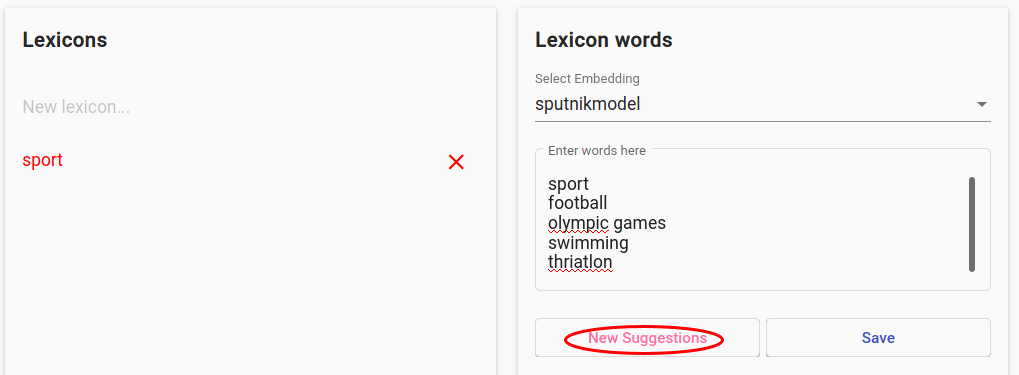
Fig. 145 Providing some seed words for before hitting “New Suggestions”¶
Provide some seedwords (example in Fig. 145), hit “New Suggestions”, click on suitable terms and repeat as long as the suggestions contain suitable terms. Then hit “Save”.
Search¶
Go to the Search page. As this example embedding was trained on lemmas field, choose the same field in the Advanced Search. Click on “Add lexicon” button and choose the saved lexicon.
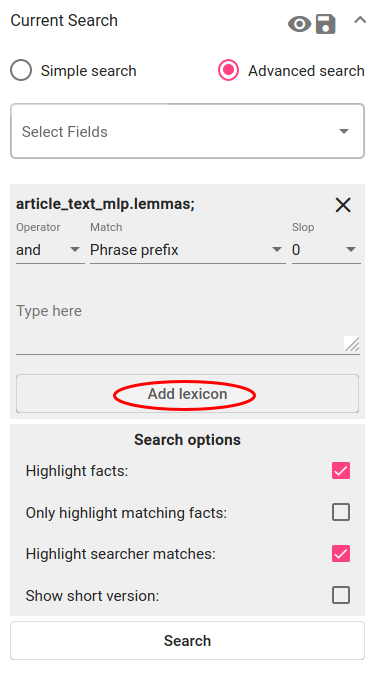
Fig. 146 Add lexicon for the search constraint¶
Choose the operator “or”. Match stays default (“Phrase prefix”) and Slop also (“0”). Click on Search.
You now have more results than just searching the term “sport”!
Bonus: aggregate over time¶
Research question: When are sport-related articles published?
In order to aggregate the documents over time, open the Aggregations panel and choose the date field (in Texta date format). Configure other options as shown in Fig. 147 or leave them as default. Click on “Aggregate”.
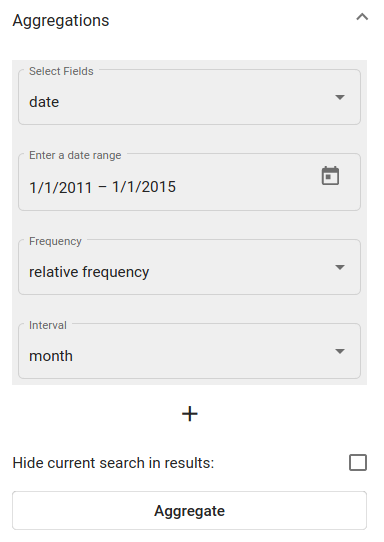
Fig. 147 Active sport-topic search results’ aggregation over date field¶
The aggregation outputs a line chart with the results. The X-axis is the raw frequency, Y-axis is the date.
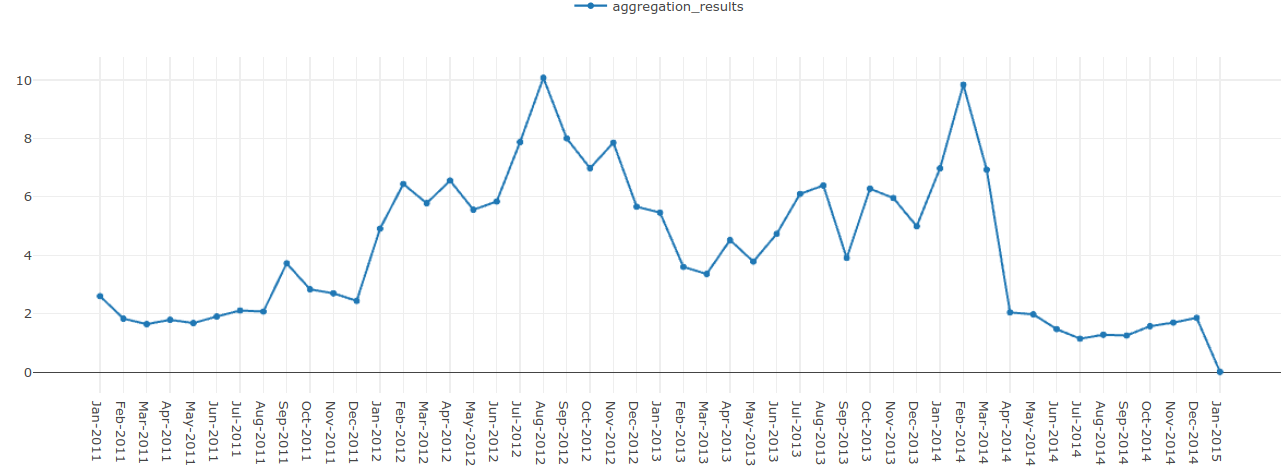
Fig. 148 Line chart of sport-related articles from 1th of January 2011 to 1th of January 2015¶
You can see that most sport-related articles are published in August 2012 and February 2014. These, surprise-surprise, overlap with the times of Summer Olympics (27th of July to 12th of August 2012) and Winter Olympics (7th of February to 23rd of February 2014).
When is this term most frequently used?¶
Research question: How frequent are the terms “communism” and “communists” in Sputnik through time?
Pre-requirements:
A project with the sputnik newspaper articles dataset is created.
This project is active (chosen on the upper panel in the right).
Searcher is open.
Search term(s)¶
Click on “Advanced search” and choose the field with the content in it (“article_text”). Fig. 149 describes the search constraint for finding documents with words that start with “communis” (e.g “communism”, “communist”, “communists”) - operator is “and” or “or”, match is “Phrase prefix” and there is no slop. Click on “Search”.
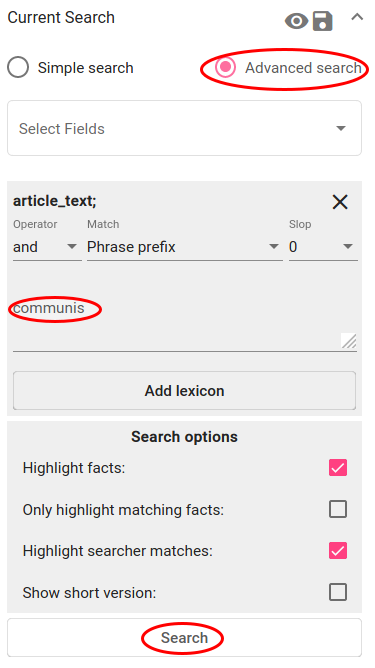
Fig. 149 Search constraint for finding communism-related articles¶
Now the table displays all the documents that the searcher with this constraint filtered out. This search result is now active. If you want, you can save it for later, but as the Aggregation works on active searches, leave it as it is.
Aggregate over time¶
To aggregate the documents over time, open the Aggregations panel and choose the date field (in Texta date format). Other options can be left as they are. Click on “Aggregate”.
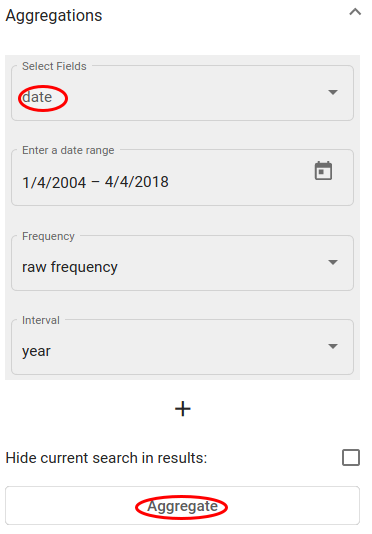
Fig. 150 Active search results’ aggregation over date field¶
The aggregation outputs a line chart with the results. The X-axis is the raw frequency, Y-axis is the date (you can change the unit on the Aggregation panel under Interval).
See more aggregating examples under Search.
Does my new document belong to this subset?¶
Goal: To train a classifier that detects whether a certain document belongs to the chosen subset of documents or not
Pre-requirements:
A project with the sputnik newspaper articles dataset is created.
This project is active (chosen on the upper panel in the right).
Create a subset of positive documents¶
When the user already has the dataset tagged in some way (dataset contains a certain Tag field with the tag, for example), they can use the Searcher to filter the tagged documents out as the positive examples and save it.
When the dataset does not already contain the tagged documents, the user can train an embedding and use the Lexicon Miner and/or the Searcher for creating some theme-related subset. There is an example of that in the first use case above.
This use case follows the first scenario and saves a subset of documents with “Middle East” in its rubric field (see Fig. 151). These will be positive examples similar to which the trained tagger later on tags also as positive. The user saves the search via floppy disk icon near the Current Search panel.
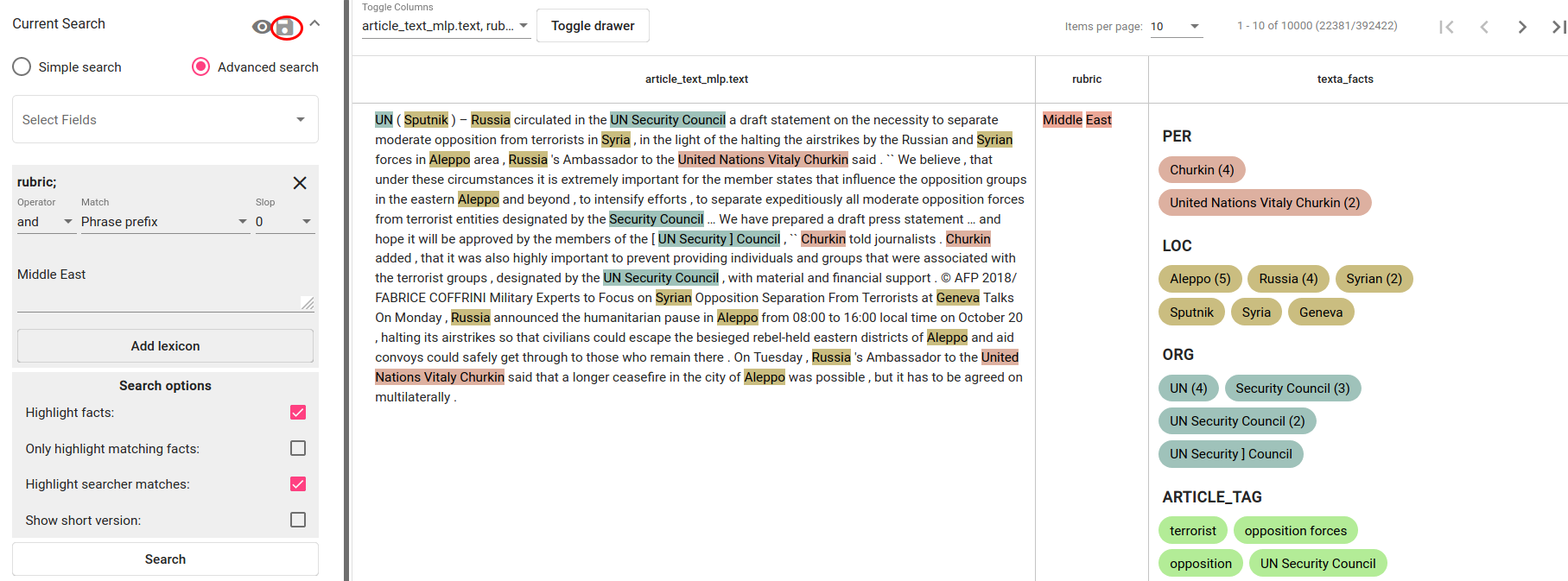
Fig. 151 Search constraint for finding articles with “Middle East” in the rubric field¶
Train the classifier¶
Under Models > Taggers a classifier (tagger) can be trained. User clicks on the “CREATE” button in the top left and chooses suitable parameters in the pop-up window. The saved search is chosen as the query. Fields “article_text_mlp.text” and “title” will be just concatenated together. User can test different vectorizers and classifiers and their parameters by training different classifiers with the same positive dataset or leave them default.
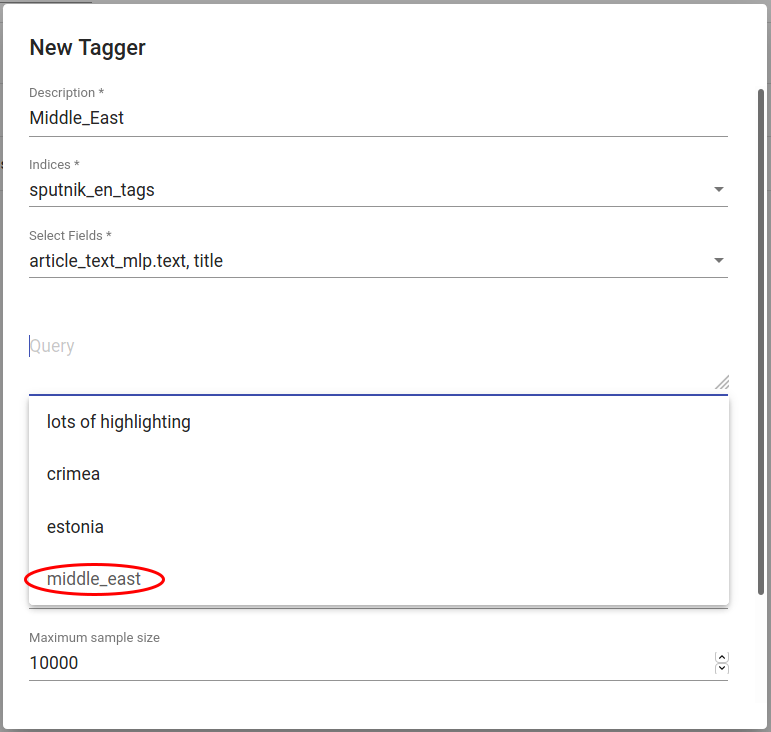
Fig. 152 Creating a classifier for tagging Middle East-related articles¶
After hitting the “Create”-button (scroll down a bit if necessary) all left to do is to wait a bit until the classifier finishes training.
Test the classifier¶
The easiest way to quickly test the new classifier is to use “tag random doc” under the three dots under Actions. This takes a random document from the dataset and outputs the tagger’s result and probability of that result being correct.
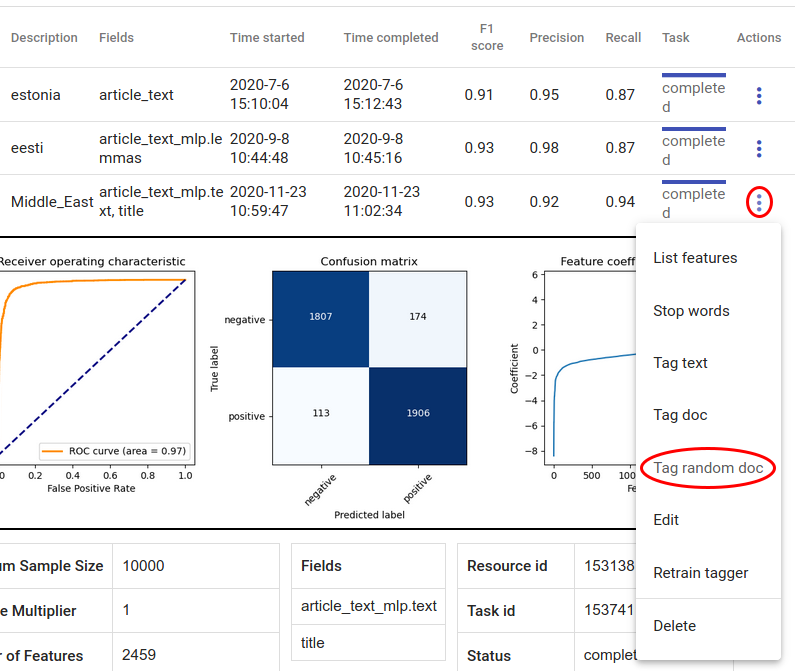
Fig. 153 Tag random doc¶
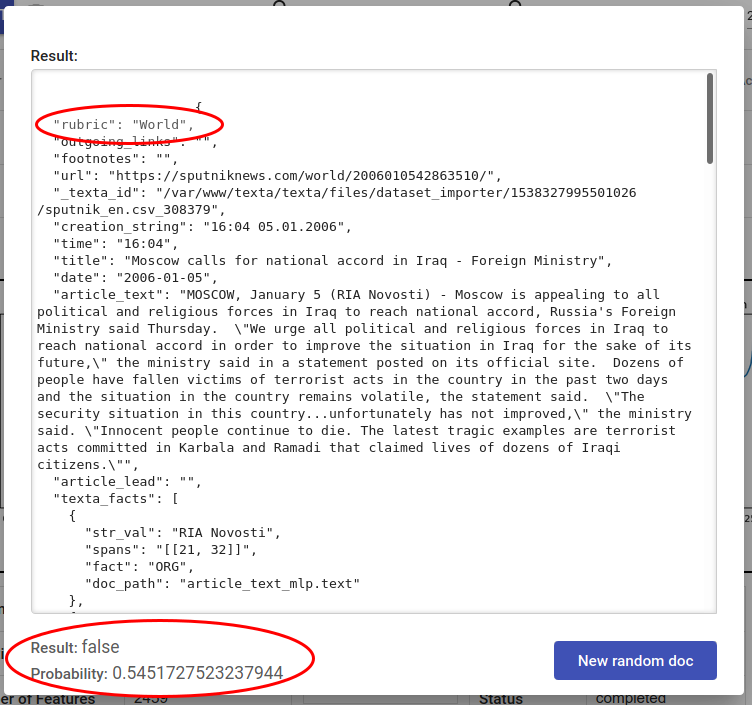
Fig. 154 Random doc is not Middle East themed and tagger outputs correctly False¶
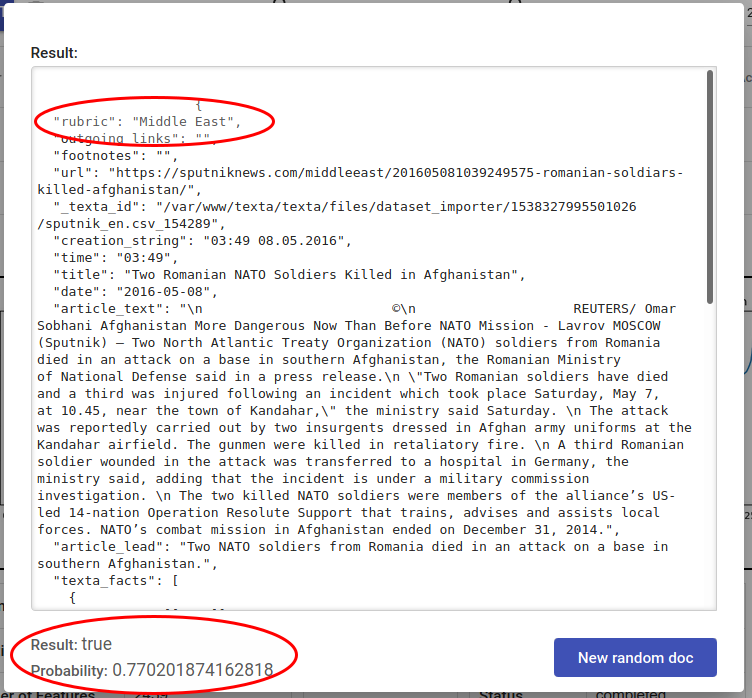
Fig. 155 Random doc is Middle East themed and tagger outputs correctly True¶
User can also paste their text into “tag text” box for classification or use the new tagger via API. Read more about these options here.