Embedding¶
Create¶
GUI¶
Navigate to Models -> Embeddings and click on the CREATE button on top-left. Choose the name for you embedding (Description). Define the query and select indices on which the query will be executed. If you leave Query empty, it will take all documents from the selected indices. If you have any searches defined in your project, they will appear in a dropdown menu if you click on the field Query - you can use existing searches as queries.
Choose fields on which the embedding will be trained. The selected fields should contain textual data.
Note
It is recommended to use lemmatized or tokenized data. Lemmatization is especially useful with morphologically complex languages. You can tokenize and lemmatize the data with MLP.
Field Number of dimensions defines the length of the word vectors. 100-200 dimensions is usually a good place to start with. Field Minimum frequency sets how many times a word must occur in the data in minimum in order to get included into the embedding. Again, you can leave it with the default value 5 if you are unsure which value to pick.
Note
The quality of the embedding depends on the size of the dataset. The larger the better.
API¶
Endpoint: /projects/{project_pk}/embeddings/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/embeddings/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "My embedding",
"indices": [{"name": "texta_test_index"}],
"fields": ["comment_content_lemmas"],
"num_dimensions": 100,
"max_documents": 10000,
"min_freq": 5
}'
View¶
GUI¶
Navigate to Models -> Embeddings to view existing embedding. If any of your embeddings is still training, the view will show you the progress of the training (Fig. 59). Besides than that, the view shows you general information about your embeddings.
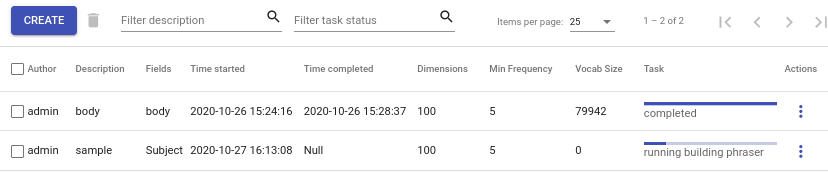
Fig. 59 Embedding view¶
API¶
Endpoint: /projects/{project_pk}/embeddings/
Example:
curl -X GET "http://localhost:8000/api/v1/projects/9/embeddings/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Delete¶
GUI¶
Navigate to Models -> Embeddings and click on the three dots under Actions column and choose Delete (Fig. 60).
Fig. 60 Embedding actions¶
API¶
Endpoint: /projects/{project_pk}/embeddings/{embedding_id}
Example:
curl -X DELETE "http://localhost:8000/api/v1/projects/9/embeddings/9/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Edit¶
GUI¶
Navigate to Models -> Embeddings and click on the three dots under Actions column and choose Edit (Fig. 60).
API¶
Endpoint: /projects/{project_pk}/embeddings/{embedding_id}
curl -X PATCH "http://localhost:8000/api/v1/projects/9/embeddings/8/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{"description":"changed"}'
Apply phraser¶
GUI¶
Navigate to Models -> Embeddings, click on the three dots under Actions and choose Phrase (Fig. 60). Insert text that you want to phrase and click Post. You should see phrased version of the text (Fig. 61).

Fig. 61 Apply phraser¶
API¶
Endpoint: /projects/{project_pk}/embeddings/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/9/embeddings/8/phrase_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "Venus is the second planet from the Sun."
}'