BERT Tagger¶
BERT Tagger is a tool for fine-tuning BERT models and using the fine-tuned models for text classification.
Creation¶
The following section covers everything we need to know about creating BERT Taggers. For getting an overview of the input parameters, see subsection Parameters; for creating a BERT Tagger via graphical user interface, see subsection GUI; for creating BERT Tagger via API, see subsection API.
Parameters¶
The following section gives an overview of BERT Tagger’s input parameters.
- description:
Name of the new fine-tuned BERT Tagger model.
- indices:
List of Elasticsearch indices containing the data being used for training the model. NB! Indices should be formatted as list of dicts, where key = “name” and value = <index_name>, e.g:
[{"name": "my_dataset"}]
- query:
Elasticsearch query query in JSON string format (in API) or as saved Search (in GUI). For binary classification, the documents corresponding to the specified query are used as positive examples.
- fields:
List of fields from the selected index/indices which are used as input data for training.
- maximum_sample_size:
Maximum number of positive examples.
- minimum_sample_size:
Minimum number of positive examples.
- fact_name:
Fact name used for multiclass classification. NB! The selected fact should have at least two unique values!
- pos_label:
Fact value used as the positive label while calculating various evaluation scores like precision, recall and f1.
Note
Defining this parameter is necessary only, if:
a) param fact name is defined and
b) the defined fact name has exactly two unique values.
- balance:
Whether or not to balance the classes for multiclass classification. If this parameter is enabled, the examples for each class are sampled with repetitions until their size is either equal to
a) the size of the class with the largest number of examples (param balance to max limit is disabled) or
b) the max limit defined with parameter maximum sample size (param balance to max limit is enabled).Note
This parameter has effect only if param fact name is defined.
- use_sentence_shuffle:
If enabled, the sentences in the additional examples added for balancing are randomly shuffled. This might be useful as the input texts are cut off after a specified limit and shuffling the additional examples will result in a more versatile training data.
- balance_to_max_limit:
If enabled, the examples for each class are sampled with repetitions until the limit set with param maximum sample size is reached.
- checkpoint_model:
A previously fine-tuned model to further fine-tune on a new data. In API, the value for this parameter should be an ID of the previously fine-tuned model.
Note
If checkpoint model is selected, the pre-trained model (param bert model) is automatically set to the one that was used for training the checkpoint model.
- bert_model:
Name of the pretrained BERT model to use. NB! Only previously downloaded models can be used. If the model you wish to use is not currently available, download it via the endpoint
/bert_taggers/download_pretrained_model/(in API) or by clicking on the button “Add pretrained model” (in GUI).
- num_epochs:
Number of epochs to train the model.
Note
It is advisable to use the default value (2) as training more than 2 epochs usually leads to overfitting.
- learning_rate:
Tuning parameter in an optimization algorithm that determines the step size at each iteration while moving toward a minimum of a loss function.
- eps:
Small term added to the denominator to improve numerical stability.
- max_length:
Maximum number of tokens used for training.
Note
If the value is higher, the results are usually better as bigger proportion of each input text is used, but setting the value too high might lead to memory problems. Setting the value higher also results in longer training time.
- batch_size:
Batch size used for training. NB! Autoscaled based on param max_length if the inserted size is too large to avoid memory errors.
- split_ratio:
Proportion of documents used for training; the others are used for validation.
- negative_multiplier:
Multiplier determining the number of negative examples. If set to 1, the number of negative examples is equal to the number of positive examples; if set to 0.5, the number of negative examples is half the number of positive examples; if set to 2, the number of negative examples is 2 times the bigger than the number of positive examples etc.
GUI¶
For creating a new BERT Tagger model, navigate to “Models” -> “Bert Taggers”. Click on the button “CREATE” in the upper left corner of the page (Fig. 130).
Fig. 130 BERT Tagger creation button¶
After clicking on the button, a new BERT Tagger creation window should open. Fill the required fields and modify the parameters you wish to change, then click on the button “Create” in the bottom right corner of the window (Fig. 131). A new row containing the information about the created tagger should now appear in the list of all BERT taggers with status “created” or “training”.
Fig. 131 BERT Tagger creation window¶
If the training process is finished (status == “completed”), you can view plots, various training parameters and evaluation results by clicking on the corresponding row.

Fig. 132 BERT Tagger row¶
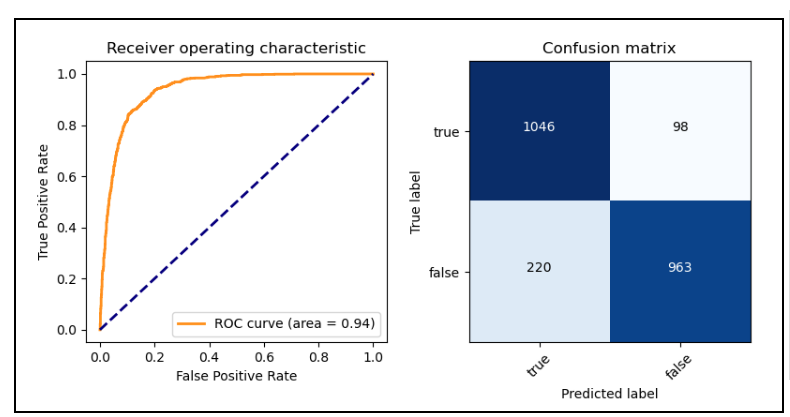
Fig. 133 BERT Tagger’s ROC curve and confusion matrix.¶
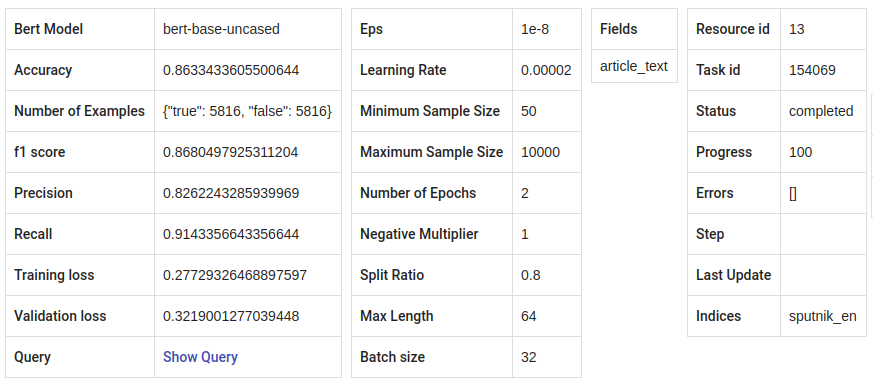
Fig. 134 BERT Tagger’s training and validation parameter values.¶
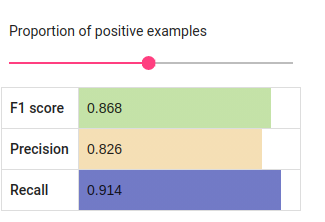
Fig. 135 BERT Tagger’s estimated results with equal number of positive and negative examples.¶
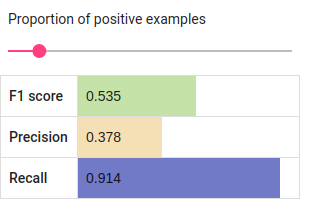
Fig. 136 BERT Tagger’s estimated results with low number of positive examples.¶
API¶
Endpoint /projects/{project_pk}/bert_taggers/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/bert_taggers/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "war_tagger",
"query":"{\"query\":{\"bool\":{\"must\":[],\"filter\":[],\"must_not\":[],\"should\":[{\"bool\":{\"must\":[{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"war\",\"type\":\"best_fields\",\"slop\":\"0\",\"fields\":[\"article_tags\"]}}],\"minimum_should_match\":1}}]}}],\"minimum_should_match\":1}}}",,
"fields": ["article_text"],
"indices": [{"name": "sputnik_en"}],
"bert_model": "bert-base-cased",
"max_length": 64
}'
Response:
{
"url": "https://rest-dev.texta.ee/api/v1/projects/291/bert_taggers/13/",
"author_username": "masula",
"id": 13,
"description": "war",
"query": "{\"query\":{\"bool\":{\"must\":[],\"filter\":[],\"must_not\":[],\"should\":[{\"bool\":{\"must\":[{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"war\",\"type\":\"best_fields\",\"slop\":\"0\",\"fields\":[\"article_tags\"]}}],\"minimum_should_match\":1}}]}}],\"minimum_should_match\":1}}}",
"fields": [
"article_text"
],
"f1_score": 0.8680497925311204,
"precision": 0.8262243285939969,
"recall": 0.9143356643356644,
"accuracy": 0.8633433605500644,
"validation_loss": 0.3219001277039448,
"training_loss": 0.27729326468897597,
"maximum_sample_size": 10000,
"minimum_sample_size": 50,
"num_epochs": 2,
"plot": "https://rest-dev.texta.ee/data/media/30ea13659e9311ca86faa5cbe2943e.png",
"task": {
"id": 154069,
"status": "completed",
"progress": 100.0,
"step": "",
"errors": "[]",
"time_started": "2021-02-12T14:01:16.878193+02:00",
"last_update": null,
"time_completed": "2021-02-12T14:09:05.597654+02:00",
"total": 0,
"num_processed": 0
},
"fact_name": null,
"indices": [
{
"id": 9,
"is_open": true,
"url": "https://rest-dev.texta.ee/api/v1/index/9/",
"name": "sputnik_en"
}
],
"bert_model": "bert-base-uncased",
"learning_rate": 2e-05,
"eps": 1e-08,
"max_length": 64,
"batch_size": 32,
"adjusted_batch_size": 26,
"split_ratio": 0.8,
"negative_multiplier": 1.0,
"num_examples": "{\"true\": 5816, \"false\": 5816}",
"confusion_matrix": "[[1046, 98], [220, 963]]"
}
Usage¶
The following section covers all functions supported by BERT Tagger.
Download Pretrained Model¶
“download_pretrained_model” allows downloading pretrained BERT models available in Hugging Face.
Note
Downloading the model might take some time (but usually not over 30 seconds), so be patient if nothing seems to happen at first!
GUI¶
TODO
API¶
Endpoint /projects/{project_pk}/bert_taggers/download_pretrained_model/
Example:
curl -X DELETE "http://localhost:8000/api/v1/projects/1/bert_taggers/131/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
-H "Content-Type: application/json" \
-d '{
"bert_model": "gilf/english-yelp-sentiment"
}'
Response (negative):
"Download finished."
Tag Random Doc¶
“Tag Random Doc” allows applying a BERT tagger model to a random document in an index.
Parameters¶
- indices
List of indices from where the random document is retrieved. Default to the indices used for training the model.
- fields
List of document fields onto which the tagger will be applied. Default to the fields used for training the model.
GUI¶
TODO
API¶
Endpoint /projects/{project_pk}/bert_taggers/{id}/tag_random_doc/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/bert_taggers/138/tag_random_doc/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{}'
Response:
{
"document": {
"rubric": "Military & Intelligence",
"outgoing_links": "['http://sputniknews.com/tags/tag_AlexanderLukashenko/']",
"footnotes": "[]",
"url": "https://sputniknews.com/military/201606161041450650-polonez-rocket-system/",
"_texta_id": "/var/www/texta/texta/files/dataset_importer/1538327995501026/sputnik_en.csv_175912",
"creation_string": "16:18 16.06.2016",
"time": "16:18",
"title": "Polonez: Belarus Successfully Test-Fires New Multiple Rocket Launch System",
"date": "2016-06-16",
"article_text": "MINSK (Sputnik) — Belarus has successfully tested its newly developed Polonez multiple launch rocket system, Belarusian President Alexander Lukashenko said Thursday. \n \"This is a happy day is terms of security and defense. With a minuscule amount of funding allocated, our military was able to develop and test what has today become Belarusian-made missile armaments. The rocket systems have been launched,\" Lukashenko said during a meeting with Belarusian Prime Minister Andrei Kobyakov and National Bank of Belarus Head Pavel Kallaur, as quoted by the Belarusian Telegraph Agency (BelTA). \n \n ©\n Sputnik/ Pavel Lisitsyn Iron Fist: Russian Uragan Multiple Rocket Launcher Becoming Deadlier The first missile hit its target with a 1.5 meter (5 foot) accuracy, while the second missile reached its target with a 10-meter accuracy, he added, praising the result and stressing that the system was created within the last two years.\n The prime minister was instructed to award those contributing to the development of the missile system, according to the media outlet. \n The Polonez system was first unveiled at the May 9, 2015 Victory Day Parade in Minsk.",
"article_lead": "The Belarusian Polonez multiple launch rocket system has successfully passed tests, President Alexander Lukashenko said.",
"article_tags": "['Polonez MLRS', 'Alexander Lukashenko', 'Belarus']",
"texta_facts": [
{
"spans": "[[0, 0]]",
"str_val": "refugees",
"fact": "TEXTA_TAG",
"doc_path": "article_text"
}
]
},
"prediction": {
"probability": 0.8746703267097473,
"tagger_id": 13,
"result": "false"
}
}
Tag Text¶
“Tag Text” enables tagging a single text with a fine-tuned BERT Tagger model.
GUI¶
TODO
API¶
Endpoint /projects/{project_pk}/bert_taggers/{id}/tag_text/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/bert_taggers/131/tag_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "Ignorance is bliss, right? According to the official US estimates, approximately 2 million civilians died in the Vietnam War while NGOs put death toll at nearly 4 million."
}'
Response:
{
"probability": 0.9773088097572327,
"tagger_id": 131,
"result": "true"
}
Available Models¶
“Available Models” returns a list of currently available pretrained BERT models.
API¶
Endpoint /projects/{project_pk}/bert_taggers/available_models/
Example:
curl -X GET "http://localhost:8000/api/v1/projects/1/available_models/" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Response:
[
"bert-base-multilingual-cased",
"EMBEDDIA/finest-bert",
"bert-base-uncased",
"tartuNLP/EstBERT",
"textattack/bert-base-uncased-imdb",
"unitary/toxic-bert",
"ProsusAI/finbert",
"distilbert-base-uncased-finetuned-sst-2-english",
"prajjwal1/bert-tiny",
"gilf/english-yelp-sentiment"
]
Note
The list will vary depending on which models have been downloaded.
Epoch Reports¶
“Epoch Reports” returns a list of reports of the results at end of each epoch. The number of reports == value of param num_epochs.
GUI¶
TODO
API¶
Endpoint /projects/{project_pk}/bert_taggers/{id}/epoch_reports/
Example:
curl -X GET "http://localhost:8000/api/v1/projects/1/bert_taggers/138/epoch_reports/" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
Response (positive):
[
{
"f1_score": 0.86351,
"precision": 0.79255,
"recall": 0.94843,
"confusion_matrix": [
[
1085,
59
],
[
284,
899
]
],
"accuracy": 0.8526,
"training_loss": 0.40053,
"validation_loss": 0.34498,
"training_time": "0:02:21",
"validation_time": "0:00:10",
"area_under_curve": 0.93035,
"classes": [
"true",
"false"
],
"epoch": 1
},
{
"f1_score": 0.86805,
"precision": 0.82622,
"recall": 0.91434,
"confusion_matrix": [
[
1046,
98
],
[
220,
963
]
],
"accuracy": 0.86334,
"training_loss": 0.27729,
"validation_loss": 0.3219,
"training_time": "0:02:22",
"validation_time": "0:00:10",
"area_under_curve": 0.93728,
"classes": [
"true",
"false"
],
"epoch": 2
}
]