MLP¶
Preprocessing the data is a standard procedure in machine learning which in TTK can be done via MLP (MultiLingual Preprocessor) module.
TEXTA MLP (Multilingual Processor) is an additional module of TEXTA created for the sake of processing and enriching textual data. Capable of processing multiple languages, it’s features include the lemmatization of text, Named Entity extraction, entity linking and more. To make access to the module more efficient and smoother, it has been integrated directly into the Toolkit. Choosing which features the user wants to apply on their text is handled by selecting “Analyzers”.
Users can apply the MLP to a singular text of their own choosing or apply it to multiple Elasticsearch indices at once.
For convenience purposes the Toolkit supports several input types along with processing several Elasticsearch indices at once, the latter however is a time consuming process depending on the size of the index and the length of the processed fields.
Analyzers¶
Analyzers are a way of selecting how you want your data to be processed, whether you only want lemmatization or Entity extraction. Currently, the following analyzers are supported:
lemmas - Adds a lemmatized version of the original text.
pos_tags - Adds the Part Of Speech tags of every token in the text.
transliteration - Adds a representation of scripted languages (Russian, Arabic) in the latin alphabet.
ner - Adds Named Entities in Texta Fact format (Please note that NER for Estonian is currently not available).
entities - Keyword based Entity Extraction, used to extract information like predefined addresses.
namemail - Extracts name-email pairs from text in Texta Facts format.
bounded - Links existing Texta Facts together by the basis of it belonging to the same Entity and returns a new Texta Fact.
Creating¶
GUI¶
Navigate to Tools -> MLP. Click Create button to define a new MLP worker. Select indices and fields on which you want to apply MLP. Since preprocessing the data is quite time-consuming process, it is strongly recommended to select only fields on which applying MLP is actually useful. That is, the fields which you are going to use later to create lexicons or train models on. Lastly, select analyzers which you would like to apply.
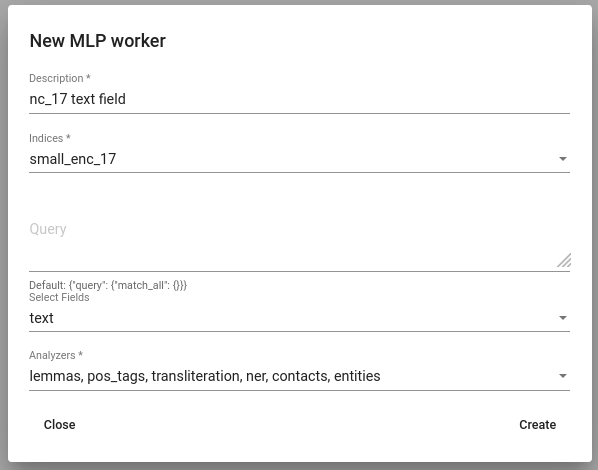
Fig. 18 Creating a MLP worker¶
The worker adds new fields containing the results to the dataset. You can see the list of fields using Search.
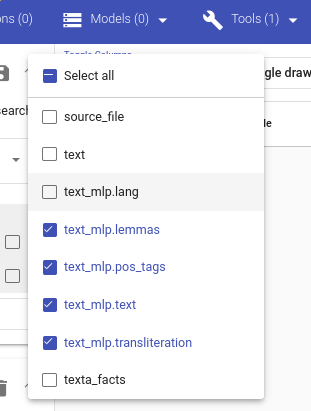
Fig. 19 Newly added fields containing results of MLP¶
Applying¶
Applying MLP on a single text instance¶
GUI¶
For applying MLP on a single instance of text, click on the “Apply to text” button inside Tools -> MLP.
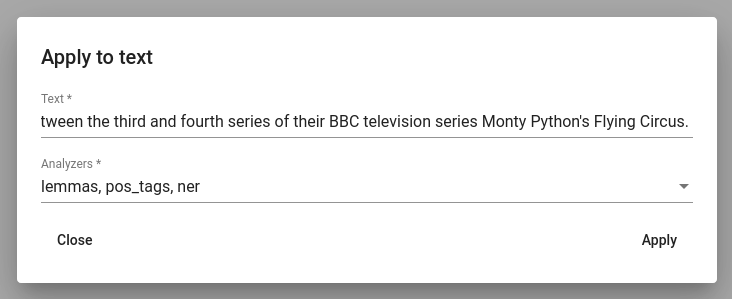
Fig. 20 Applying MLP on a single instance of text.¶
API¶
Endpoint: /mlp/texts/
This takes input in list format. Just use a single-element list.
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/mlp/texts/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"texts": ["Mis su nimi on?"]
}'
Response:
[
{
"text": {"text":"Mis su nimi on ?","lang":"et","lemmas":"mis sina nimi olema ?","pos_tags":"P P S V Z"},
"texta_facts":[]
}
]
Applying MLP on a list of texts¶
API¶
Endpoint: /mlp/texts/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/mlp/texts/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"texts": ["Mis su nimi on?", "Ettepanek minna üle neljapäevasele töönädalale lükati tagasi."]
}'
Response:
[
{
"text": {"text":"Mis su nimi on ?","lang":"et","lemmas":"mis sina nimi olema ?","pos_tags":"P P S V Z"},
"texta_facts":[]
},
{
"text": {"text":"Ettepanek minna üle neljapäevasele töönädalale lükati tagasi .","lang":"et","lemmas":"ettepanek minema üle neljapäevane töönädal lükkama tagasi .","pos_tags":"S V K A S V D Z"},
"texta_facts":[]
}
]
Applying MLP on a list of dictionaries¶
API¶
Endpoint: /mlp/docs/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/mlp/texts/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"docs": [{"comment": "Ettepanek minna üle neljapäevasele töönädalale lükati tagasi."}],
"fields_to_parse": ["comment"]
}'
Response:
[
{
"comment": "Ettepanek minna üle neljapäevasele töönädalale lükati tagasi.",
"comment_mlp": {
"text": "Ettepanek minna üle neljapäevasele töönädalale lükati tagasi .",
"lang": "et",
"lemmas": "ettepanek minema üle neljapäevane töönädal lükkama tagasi .",
"pos_tags": "S V K A S V D Z"
},
"texta_facts": []
}
]
Applying MLP on index¶
API¶
Endpoint: /mlp_index/
Withholding the analyzers field will make it default into using all analyzers which is time-insufficient.
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/mlp_index/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"indices": [{"name": "embedding_index"}],
"description": "lemmas for embedding index",
"fields": ["comment_content", "comment_title"]
}'
Response:
{
"id": 17,
"url": "https://rest-dev.texta.ee/api/v1/projects/109/mlp_index/17/",
"author_username": "texta",
"indices": [
{
"id": 30,
"is_open": true,
"url": "https://rest-dev.texta.ee/api/v1/index/30/",
"name": "embedding_index"
}
],
"description": "lemmas for embedding index",
"task": {
"id": 153759,
"status": "created",
"progress": 0.0,
"step": "",
"errors": "[]",
"time_started": "2020-12-09T10:28:59.856498+02:00",
"last_update": null,
"time_completed": null,
"total": 0,
"num_processed": 0
},
"query": {"query": {"match_all": {}}},
"fields": ["comment_content", "comment_title"],
"analyzers": ["all"]
}