Kasutuslood¶
Siin näidatakse, kuidas kasutada erinevaid Texta Toolkiti tööriistu erinevatele uurimisküsimusele vastamiseks.
Kuidas otsida kindla teemaga artikleid, kui Sa ei tea piisavalt teemasõnu?¶
Uurimisküsimus: Milline on sporditeemaliste dokumentide sagedus läbi aja?
Eeldused:
See projekt on aktiivne (valitud ülaplaneelil paremal).
Treeni keelemudel (embedding)¶
Mine Models > Embeddings. Klõpsa „CREATE“-nupul ülal vasakul. Loo keelemudel (Joonis 144). Loe rohkem keelemudelite parameetrite kohta siit.
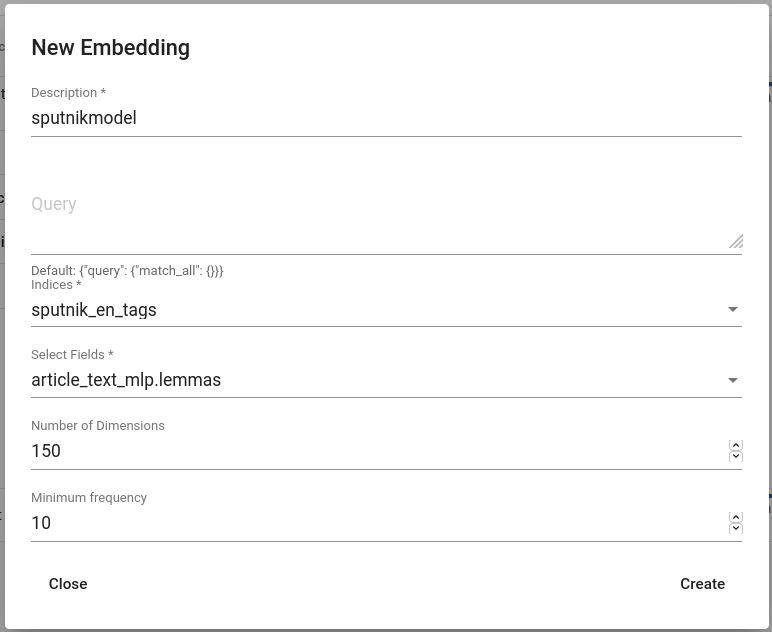
Joonis 144 Sputniku keelemudeli loomine¶
See võib võtta natukene aega. Kui keelemudel on treenitud, saab kasutada Lexicon Minerit.
Kasuta Lexicon Minerit¶
Kasuta Lexicon Minerit sproditeemaliste sõnade kaevandamiseks.
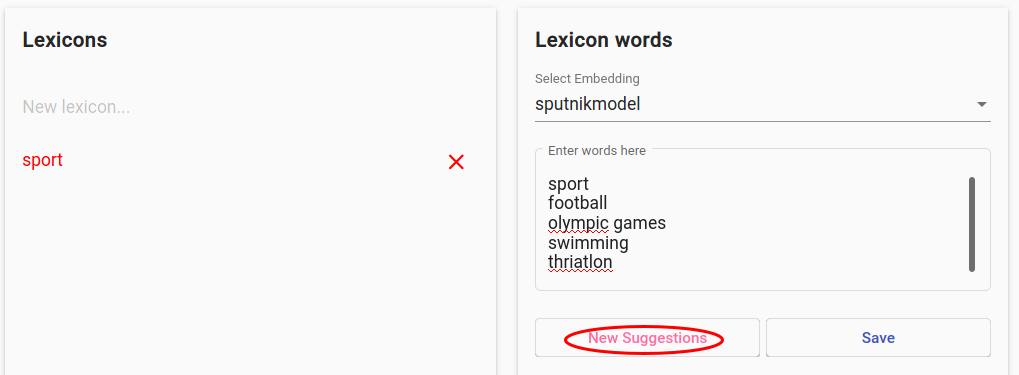
Joonis 145 Seemnesõnade sisestamine enne „New Suggestions“-nupule vajutamist¶
Sisesta mõned seemnesõnad (näidis Joonis 145), klõpsa „New Suggestions“-nupul, vajuta sobivatele terminitele ja korda tegevust kuni soovitused (suggestions) sisaldavad veel sobivaid termineid. Seejärel vajuta „Save“.
Otsi dokumente¶
Mine Otsingu (Search) lehele. Kuna keelemudel treeniti lemmade väljal, tuleb valida sama väli ka Advanced Searchis. Vajuta „Add lexicon“-nupule ja vali salvestatud leksikon.
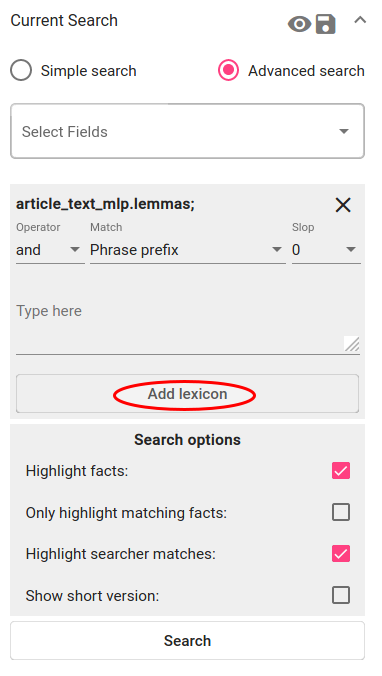
Joonis 146 Lisa leksikon otsingufiltritesse¶
Vali operaator „or“. Match jääb vaikimisi „Phrase prefix“, samuti jääb vaikimisi Slop („0“). Vajuta Search.
Nüüd saad rohkem tulemusi, kui otsid lihtsalt terminit „sport“!
Lisa¶
Uurimisküsimus: Kas spordiga seotud artiklite arvukus varieerub ajas?
Ava Aggregations paneel ja vali kuupäeva väli (Texta kuupäeva formaadis) dokumentide agregeerimiseks ajagraafikul.Seadista teisi valikuid nagu on näidatud Joonis 147 või jäta need vaikimisi. Vajuta „Aggregate“- nupule.
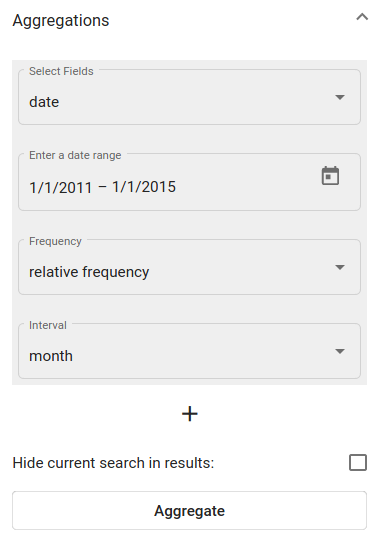
Joonis 147 Aktiivse spordi-teemalise otsingu tulemuste agregatsioon kuupäevaväljal¶
See väljastab joondiagrammi, mille X-teljel on sagedus ja Y-teljel kuupäev.
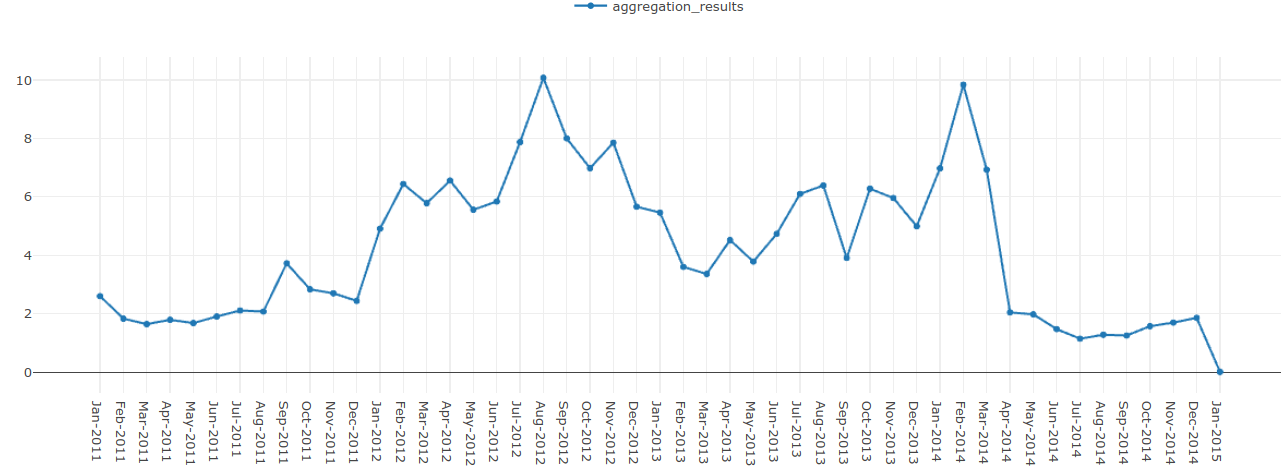
Joonis 148 Joondiagramm spodriteemaliste artiklite kohta vahemikus 01.01.2011-01.01.2015¶
Jooniselt on näha, et enim sporditeemalisi artikleid avaladati 2012. aasta augustis ning 2014. aasta veebruaris. Need kattuvad, üllatus-üllatus, suveolümpia (27.07.2012-12.08.2012) ja taliolümpia (07.02.2014-23.02.2014) kuupäevadega.
Millal on see termin kõige rohkem kasutusel olnud?¶
Uurimisküsimus: Kui sagedalt kasutatakse termineid „communism“ ja „communists“ Sputniku andmestikus läbi aja?
Eeldused:
See projekt on aktiivne (valitud ülaplaneelil paremal).
Searcher on avatud.
Otsi termit/termineid¶
Vajuta „Advanced search“ nupule ja vali väli, millel on artikli sisu („article_text“). Joonis 149 kujutab otsingupiiranguid, mis tagastavad dokumente, kus on sõnad, mis algavad tähtedega „communis“ (nt „communism“, „communist“, „communists“) - operaator on „and“ või „or“, match on „Phrase prefix“ ning slop on 0. Vajuta „Search“-nupule.
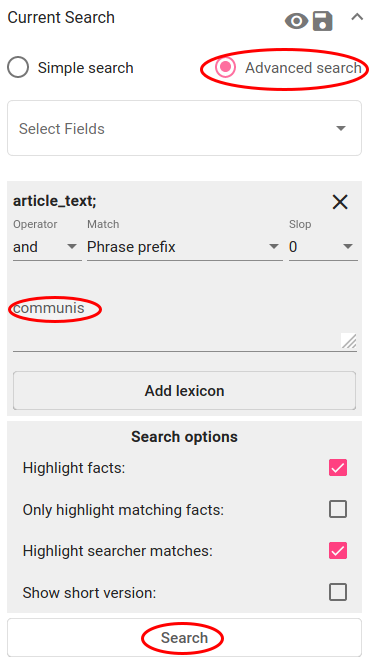
Joonis 149 Otsingupiirangud kommunismiga seotud artiklite leidmiseks inglise keeles¶
Nüüd kuvatakse tablis kõik dokumendid (tegelikult esimesed 10000), mille need piirangud välja filtreerisid. Otsingutulemus on nüüd aktiivne. Soovi korral võib selle pärastiseks salvestada, aga kuna agregeerimine töötab aktiivsete otsingute põhjal, jäta tulemus nii nagu on.
Agregeeri üle aja¶
Ava Aggregations paneel ja vali kuupäeva väli (Texta kuupäeva formaadis) dokumentide agregeerimiseks ajagraafikul.Seadista teisi valikuid nagu on näidatud Joonis 147 või jäta need vaikimisi. Vajuta „Aggregate“- nupule.
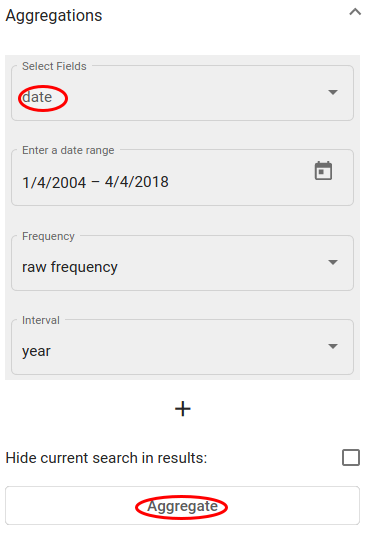
Joonis 150 *Aktiivse otsingu agregatsioon üle kuupäeva välja¶
Agregeerimisetulemused väljastatakse joondiagrammil. X-teljel on sagedus, Y-teljel on kuupäev (intervalli on võimalik muuta Aggregation paneelil Interval valiku all, kui kuupäevaformaat seda võimaldab)
Vaata rohkem agregeerimise näiteid Search all.
Kas mu uus dokument kuulub sellesse alamhulka?¶
Eesmärk: Treenida klassifitseerija, mis ennustab, kas teatud dokumentkuulub valitud dokumentide alamhulka või mitte
Eeldused:
See projekt on aktiivne (valitud ülaplaneelil paremal).
Loo positiivsete dokumentide alamhulk¶
Kui kasutajal juba on andmestik mingil moel märgendatud (näiteks on andmestikus teatud märgendiväli vastava märgendiga), saavad nad kasutada Searcherit nende dokumentide kui positiivsete näidete välja filtreerimiseks ja salvestamiseks salvestatud otsinguga.
Kui andmestikus ei ole eelnevalt märgendatud dokumente, saab kasutaja treenida embeddingu ning kasutada Lexicon Minerit ja Searcherit vastavateemalise alamhulga loomiseks. Esimeses kasutusloos on selle kohta näide.
See kasutuslugu järgib esimest stsenaariumit ning salvestab sisuga „Middle East“ rubric väljaga dokumentide alamhulga (vt Joonis 151). Nendest saavad positiivsed näited, mille sarnaseid treenitav mudel positiivseks ennustama hakkab. Kasutaja salvestab otsingu vajutades disketi ikoonile Current Searchi paneelil.
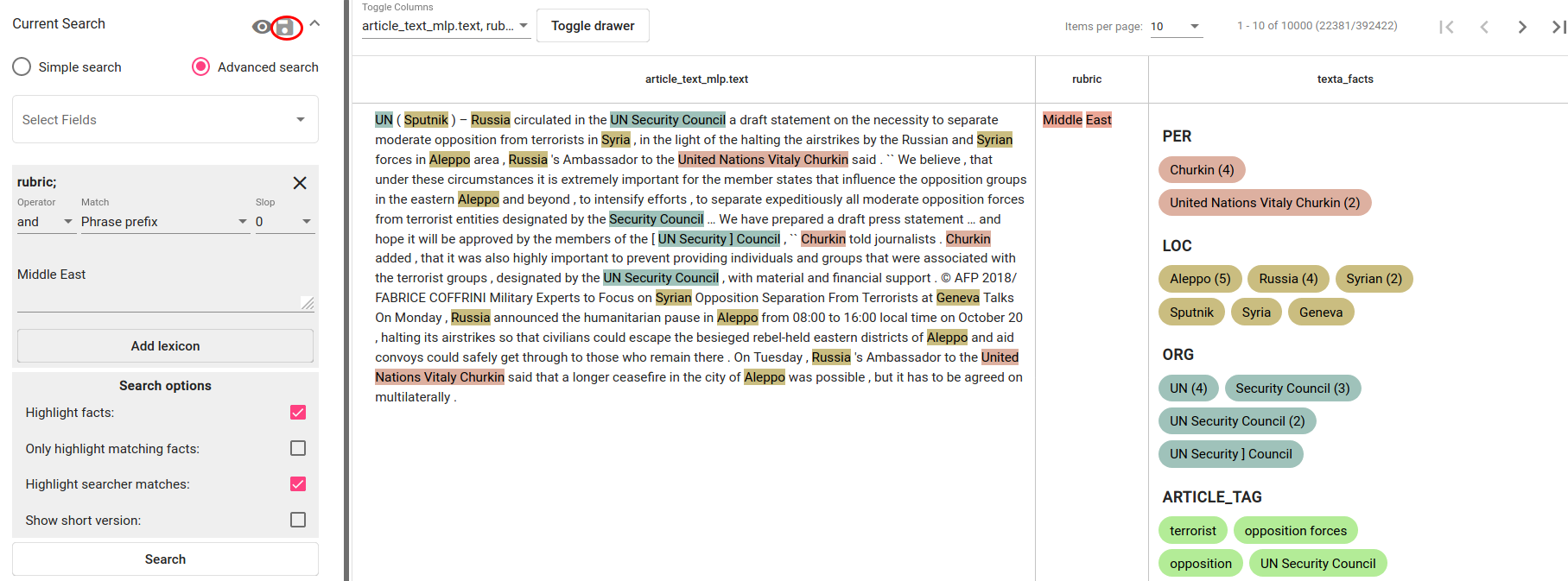
Joonis 151 *Otsingu piirangud, mis leiavad artiklid, mille rubric väljal on „Middle East“¶
Treeni klassifitseerija¶
Models > Taggers all saab treenida klassifitseerija ehk taggeri ehk märgendaja. Kasutaja klõpsab „CREATE“-nupule ülal vasakul ning valib sobivad parameetrid ilumunud aknas. Salvestatud otsing valitakse kui päring (query). Väljad „article_text_mlp.text“ ja „title“ kleebitakse enne treenimist kokku üheks sisendiks. Kasutaja saab testida erinevaid vektoriseerijaid ja klassifitseerijaid oma parameetritega treenides erinevaid klassifitseerijaid sama alamhulga peal. Soovi korral võib treenida ka vaikimisi parameetritega.
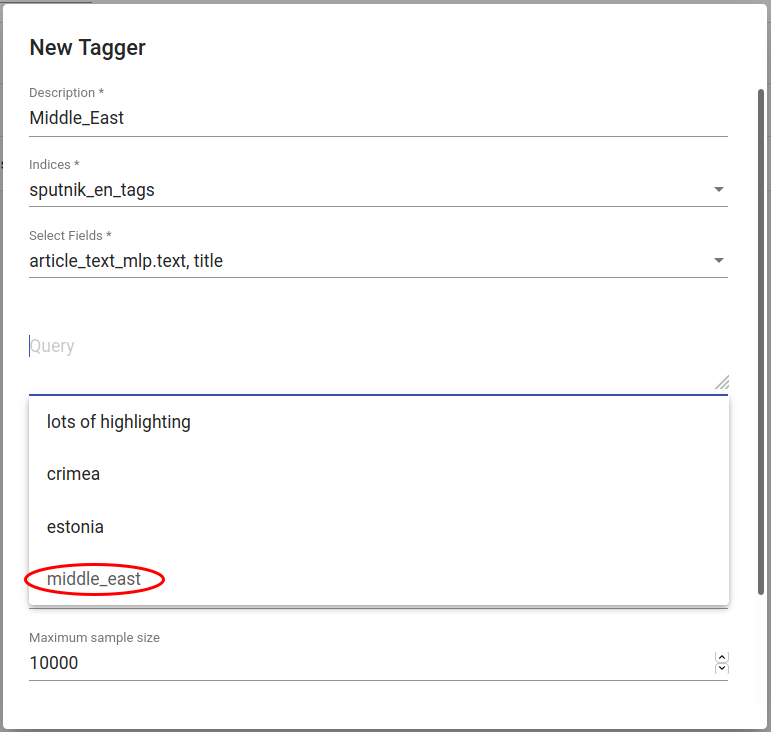
Joonis 152 Artiklite, mille tegelik rubriik (rubric väli) on Middle East, klassifitseerija loomine¶
Pärast „Create“-nupu vajutamist (vajadusel keri pisut alla), jääb üle vaid oodata, kuni klassifitseerija treenib.
Testi klassifitseerijat¶
Kergeim viis kiiresti testida uue klassifitseerija tulemusi on kasutada „tag random doc“ valikut kolme nupu all (Actioni all). See võtab juhusliku dokumendi andmestikust ning väljastab taggeri tulemuse ja selle õigsuse tõenäosuse (probability).
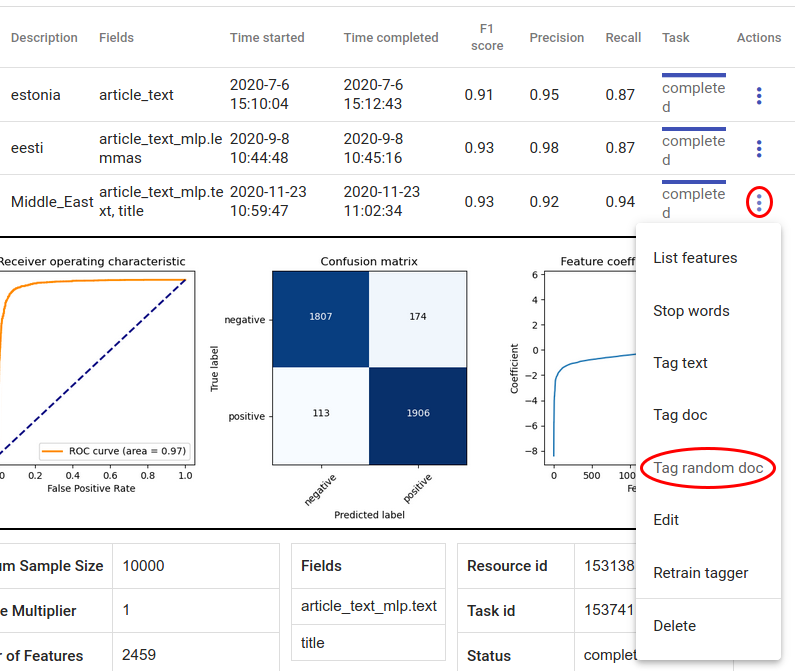
Joonis 153 Tag random doc¶
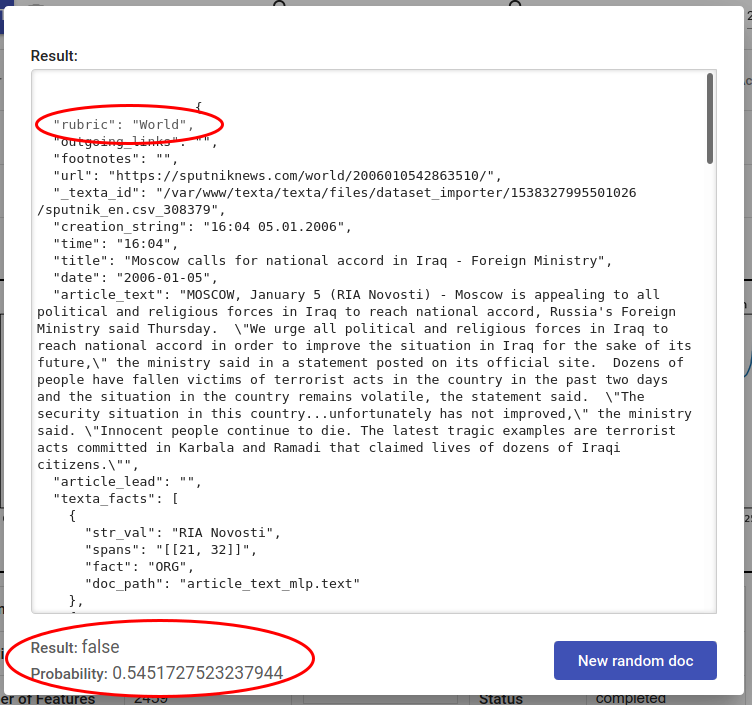
Joonis 154 Juhuslik dokument ei ole Middle East teemaline ning tagger väljastab False (mitte märgendada)¶
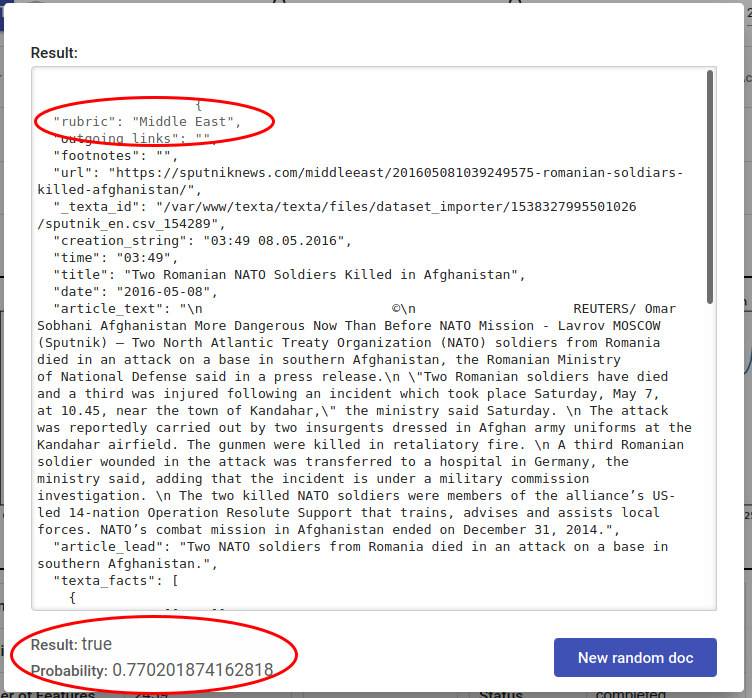
Joonis 155 Juhuslik dokument on Middle East teemaline ja tagger väljastab õigesti True (märgendada)¶
Kasutaja saab ka oma teksti testida „tag text“ valikuga või taggerit API kaudu kasutades. Loe rohkem nende valikute kohta siit.