Regex Tagger Group¶
Regex Tagger Group (Regex Taggerite grupp) on tööriist Regex Taggeri mudelite grupeerimiseks, et neid seejäral andmete märgendamiseks kasutada. Tulemuseks saadud märgendid on vormindatud Texta Facts formaadis.
API viide: http://localhost:8000/api/v1/redoc/#tag/projects-greater-regex_tagger_groups
Loomine¶
Märkus
Regex Tagger Groupi on võimalik luua üksnes juhul, kui eksisteerib vähemalt üks Regex Taggeri mudel.
Parameetrid¶
Sisend¶
- regex_taggers:
Gruppi lisatavad Regex Taggeri mudelid.
- description:
Regex Taggeri Groupi nimi, mida kasutatakse hiljem ühtlasi dokumentide märgendina. Märgendamise käigus lisatakse Regex Taggeri Groupi nimi järgnevale väljale:
API:
texta_facts.fact
GUI:
texta_facts.fact_name
Väljund¶
- id:
Loodud Regex Tagger Groupi ID.
- url:
Loodud Regex Tagger Groupi URL.
- regex_taggers:
Gruppi kuuluvate Regex Taggeri mudelite ID-d.
- author_username:
Regex Tagger Groupi looja.
- task:
Grupiga seotud Celery protsess.
- description:
Loodud Regex Tagger Groupi nimi.
- tagger_info:
Iga gruppi kuuluva Regex Taggeri mudeli parameetrid.
GUI¶
Uue Regex Tagger Groupi loomiseks navigeeri „Models“ -> „Regex Tagger Groups“ nagu kujutatud joonisel Joonis 103.
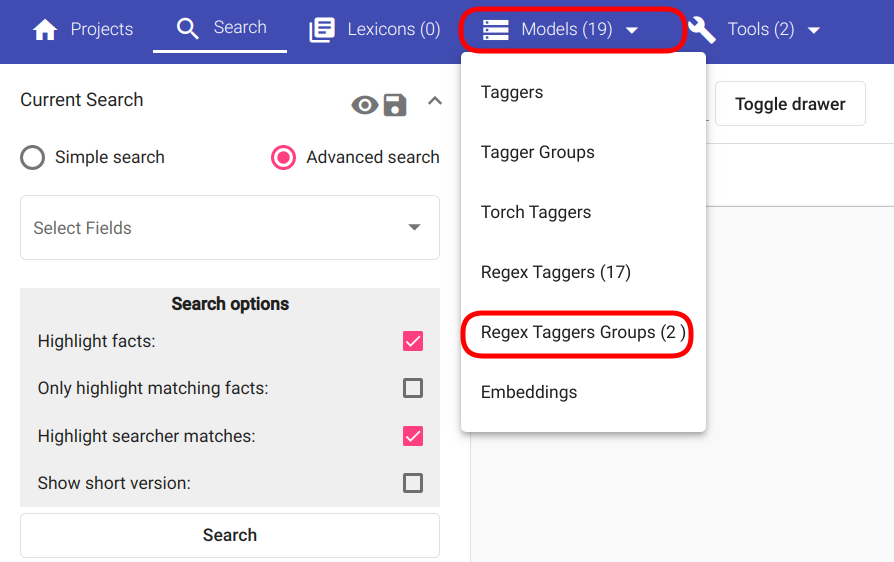
Joonis 103 Navigatsioon Regex Tagger Groupini¶
Eduka navigatsiooni korral peaksid nägema joonisega Joonis 104 sarnast lehekülge, mille ülemises vasaskus nurgas asub nupp nimega „Create“.
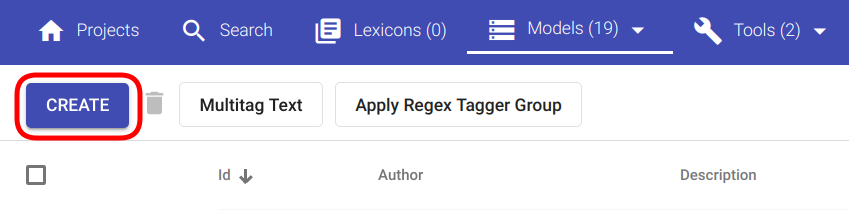
Joonis 104 Regex Tagger Groupi loomisnupp¶
„Create“ nupule vajutamise tagajärjel avaneb uus aken pealkirjaga „New Regex Tagger Group“ nagu kujutatud joonisel Joonis 105.
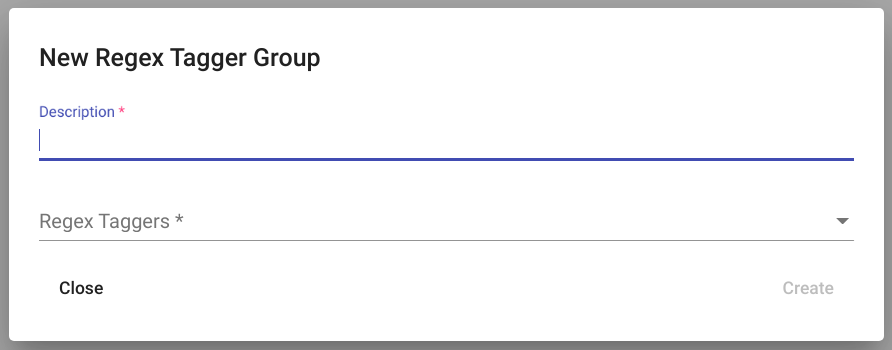
Joonis 105 Täitmata väljadega „Regex Tagger Group“ loomisaken¶
Anna Regex Tagger Groupile nimi sisestades see väljale „Description“ ning vali gruppi lisatavad Regex Taggeri mudelid mudelite välja`“Regex Taggers“` alt avanevast valikmenüüst. Valitud sisendparameetritega Regex Taggeri Groupi loomiseks vajuta akna almuses paremas nurgas asuvale nupule „Create“ (Joonis 106).
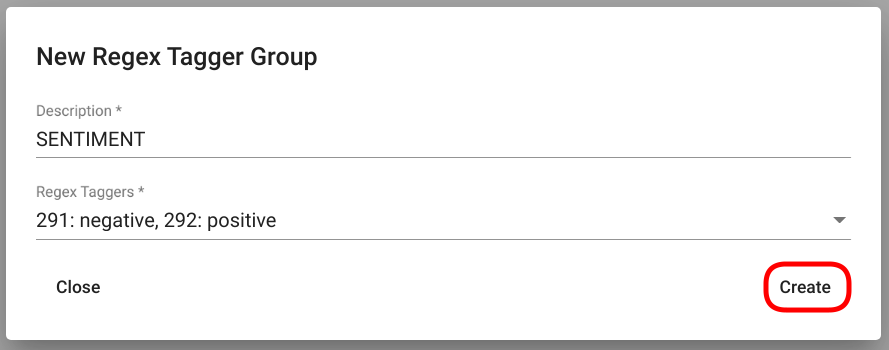
Joonis 106 Täidetud väljadega „Regex Tagger Groupi“ loomisaken¶
Loodud Regex Tagger Group ilmub nüüd Regex Tagger Groupide tabelisse (Joonis 107).

Joonis 107 Nimekiri eksisteerivatest Regex Tagger Groupidest.¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_create
Otspunkt /projects/{project_pk}/regex_tagger_groups/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"regex_taggers": [293, 294, 295],
"description": "RATING"
}'
Vastus:
{
"id": 42,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/42/",
"regex_taggers": [
293,
294,
295
],
"author_username": "masula",
"task": null,
"description": "RATING",
"tagger_info": [
{
"id": 293,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/293/",
"author_username": "masula",
"description": "bad",
"lexicon": [
"\\W*[1-4]/10\\W*",
"\\W*[1-4] out of 10\\W*",
"\\W*[1-2]/5\\W*",
"\\W*[1-2] out of 5\\W*",
"\\W*[1-4]/10\\W*",
"\\W*[1-4] stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
},
{
"id": 294,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/294/",
"author_username": "masula",
"description": "average",
"lexicon": [
"\\W*[5-6]/10\\W*",
"\\W*[5-6] out of 10\\W*",
"\\W*[3]/5\\W*",
"\\W*[3] out of 5\\W*",
"\\W*[5-6]/10\\W*",
"\\W*[5-6] stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
},
{
"id": 295,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/295/",
"author_username": "masula",
"description": "good",
"lexicon": [
"\\W*([7-9]|10)/10\\W*",
"\\W*([7-9]|10) out of 10\\W*",
"\\W*[4-5]/5\\W*",
"\\W*[4-5] out of 5\\W*",
"\\W*([7-9]|10)/10\\W*",
"\\W*([7-9]|10) stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
}
]
}
Kasutamine¶
Apply Tagger Group¶
Funktsioon „Apply Tagger Group“ on mõeldud Regex Tagger Groupi rakendamiseks Elasticsearchis indekseeritud andmestikele. Märgendamise tulemused kajastuvad väljas „texta_facts“ järgnevalt:
RegexTaggerGroup.description -> texta_fact.fact (API) / texta_fact.fact_name (GUI)
RegexTagger.description -> texta_fact.str_val / texta_fact.fact_value (GUI)
Parameetrid¶
- description:
Rakendusprotsessi nimi.
- indices:
Elasticsearchis indekseeritud indeksid (andmestikud), millele valitud mudel(id) rakendada. NB! Admestikud peavad olema vormindatud JSON sõnastikena, milles võti = „name“ ja väärtus = <andmestiku_nimi>, nt:
{"name": "my_dataset"}
- fields:
Nimekiri väljadest, millele valitud mudeleid rakendada.
- query:
Elasticsearci Search päring.
- bulk_size:
Ühes partiis töödeldavate dokumentide arv.
- max_chunk_bytes:
TODO
- regex_tagger_groups:
Rakendatavad Regex Tagger Groupid.
Märkus
Toetatud ainult graafilises kasutajaliideses.
GUI¶
Regex Taggeri Groupi(de) rakendamiseks Elasticsearchi indekseeritud andmestikele, navigeeri „Models“ -> „Regex Tagger Groups“ nagu kujutatud joonisel Joonis 103. Vajuta nupule „Apply Regex Tagger Group“ (Joonis 108).

Joonis 108 Nupp „Apply Regex Tagger Group“¶
Nupule vajutamise tagajärjel avaneb uus modaalaken pealkirjaga „Apply Regex Tagger Group to indices“. Täida nõutud väljas (vt. ka: parameetrid). PS! Jäta väli „Query“ tühjaks, kui soovid mudeleid rakendada kõikidele andmestikus olevatele dokumentidele. Pärast nõutud väljade täitmist, vajuta akna alumises paremas nurgas asetsevale nupule „Apply“ (Joonis 109).
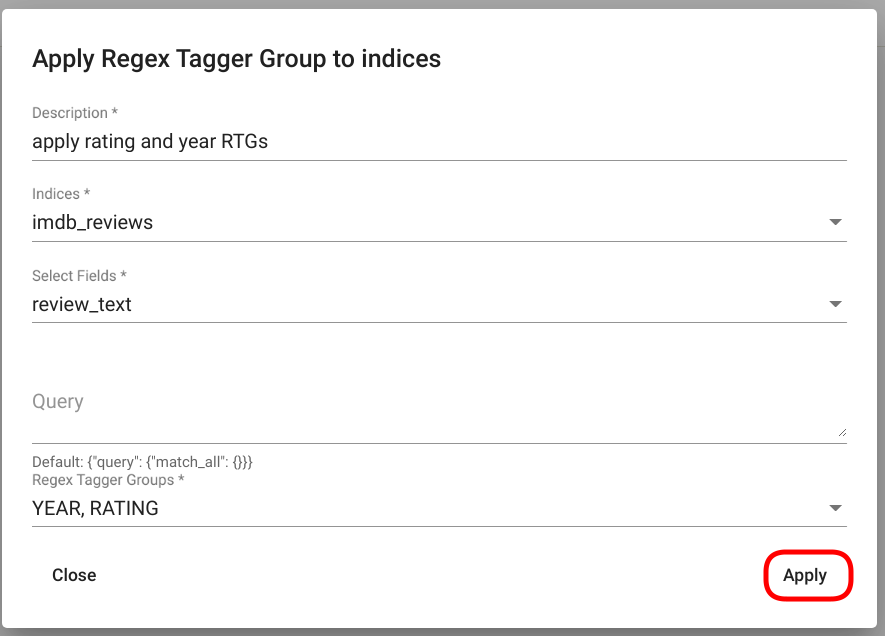
Joonis 109 „Apply Regex Tagger Group“ aken¶
Kui rakendamise protsessi loomine õnnestus, kuvatakse valitud Regex Tagger Groupi mudeli(te) „Task“ väljas staatus „created“ või „running“ nagu kujutatud joonisel Joonis 110.
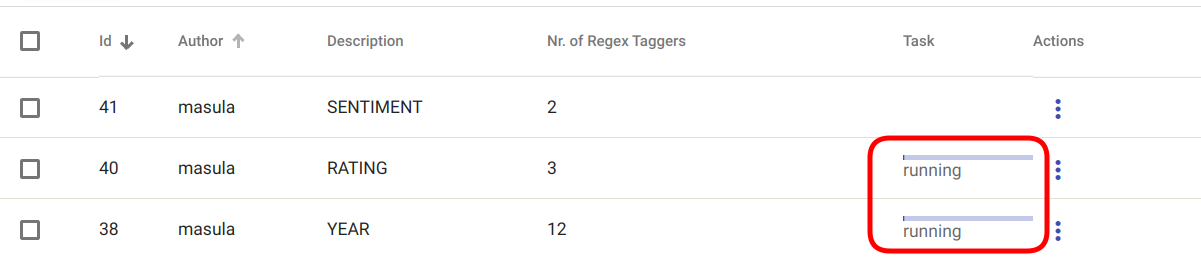
Joonis 110 „Apply Regex Tagger Group“ protsess on edukalt loodud¶
Pärast märgendamise protsessi lõpule jõudmist, saab tulemusi näha Search vaates (Joonis 111). Loodud märgendid asuvad väljal „texta_facts“.

Joonis 111 „Apply Regex Tagger Group“ väljund Search vaates.¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_apply_tagger_group
Otspunkt /projects/{project_pk}/regex_tagger_groups/{id}/apply_tagger_group/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/apply_tagger_group/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "apply my regex tagger group",
"indices": [{"name": "imdb_reviews"}],
"fields": ["review_text"],
"bulk_size": 100
}'
Vastus:
{
"message": "Started process of applying RegexTaggerGroup with id: 40"
}
Delete¶
Funktsioon „Delete“ võimaldab Regex Tagger Groupide kustutamist.
Märkus
Regex Tagger Groupi kustutamisel EI kustu sellesse kuulunud Regex Taggeri mudelid.
GUI¶
Regex Tagger Groupi kustutamiseks navigeeri „Models“ -> „Regex Tagger Groups“ nagu kujutatud joonisel Joonis 103. Regex Tagger Groupi kustutamiseks on kaks võimalust:
Variant 1:
Vali Regex Tagger Group, mida soovid kustutada, avades vastava grupi rea lõpus asuvale kolmele vertikaalsele punktile klikkides valikmenüü. Vali avanenud menüüst „Delete“ nagu kujutatud joonisel Joonis 112.
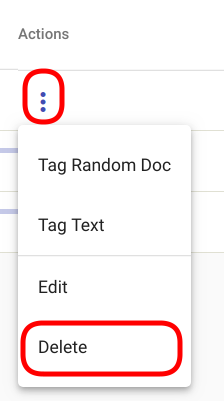
Joonis 112 Regex Tagger Groupi kustutamine¶
Variant 2:
Tee märge kõikide mudelite ette, mida kustutada soovid. Seejärel vajuta lehe ülemises vasakus nurgas asuvale punasele prügikastiikooniile Regex Tagger Groupi mudelite tabeli kohal. (Joonis 113).
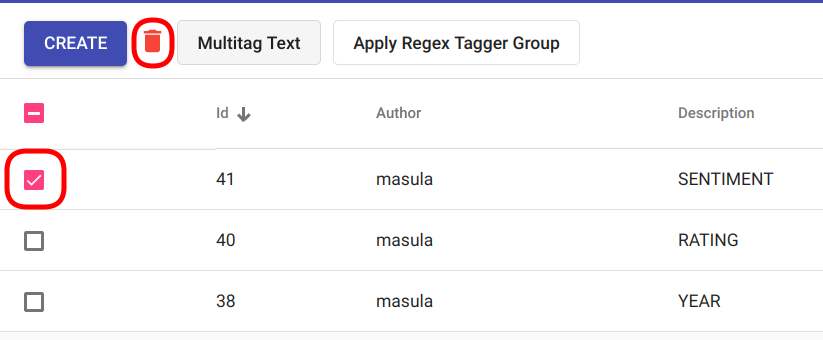
Joonis 113 Bulk delete Regex Tagger Group(s)¶
Pärast emma-kumma versiooni eelkirjeldatud sammude läbimist küsitakse enne mudeli(te) lõplikku kustutamist kasutajalt kinnitust (Joonis 114). Vajuta protsessi lõpuleviimiseks kinnituskanas nupule „Delete“.
Joonis 114 Regex Tagger Groupi(de) kustutamise kinnitusaken.¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_delete
Otspunkt /projects/{project_pk}/regex_tagger_groups/{id}/
Näide:
curl -X DELETE "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Edit¶
GUI¶
Regex Tagger Groupi muutmiseks navigeeri vastava grupi valikmenüüle vajutades kolmele vertikaalsele punktile valitud Regex Tagger Groupi rea lõpus. Vali avanenud menüüst „Edit“ nagu kujutatud joonisel Joonis 115.
Joonis 115 Regex Tagger Group -> Edit¶
Valiku sooritamise tagajärjel avaneb uus aken pealkirjaga „Edit Regex Tagger Group“. Tee soovitud muudatused ning vajuta nende jõustumiseks akna alumises paremas nurgas asuvale nupule „Apply“ (Joonis 116).

Joonis 116 Muutmisaken „Edit Regex Tagger Group“¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_update
Otspunkt /projects/{project_pk}/regex_tagger_groups/{id}/
Näide:
curl -X PATCH "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "UPDATED_REGEX_TAGGER_MODEL_NAME"
}'
Multitag Docs¶
Funktsioon „Multitag Docs“ võimaldab mitme Regex Taggeri Groupi üheaegset rakendamist etteantud dokumentidele. Iga dokumendi märgendid kajastuvad vastavale dokumendile lisatud väljas „texta_facts“ järgneva loogika alusel:
RegexTaggerGroup.description -> texta_fact.fact (API) / texta_fact.fact_name (GUI)
RegexTagger.description -> texta_fact.str_val (API) / texta_fact.fact_value (GUI)
RegexTagger.match.spans -> texta_fact.spans
field -> texta_fact.doc_path
Parameetrid¶
Sisend¶
- docs:
Märgendatavad dokumendid vormindatud JSON sõnastikuna, nt:
[ { "doc_id": 24, "title": "some title", "text": "foo bar" }, { "doc_id": 56, "title": "some other title", "text": "bar foo" } ]
- fields:
Nimekiri väljadest, millele valitud mudeleid rakendada.
- tagger_groups:
Nimekiri märgendamiseks kasutatavate Regex Tagger Groupide ID-dest.
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_multitag_docs
Otspunkt /projects/{project_pk}/regex_tagger_groups/multitag_docs/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/multitag_docs/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"docs": [
{
"review_text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films of 2015. I will give it 2 out of 10.",
"id": "27252",
"author": "jster976"
},
{
"review_text": "Absolute garbage! Would not even recommend to my worst enemy. 1/10.",
"id": "38272",
"author": "dolan87"
}
],
"fields": ["review_text"],
"tagger_groups": [38, 40, 41]
}'
Vastus:
[
{
"author": "jster976",
"id": "27252",
"review_text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films of 2015. I will give it 2 out of 10.",
"texta_facts": [
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[54, 64]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}",
"spans": "[[94, 105]]",
"str_val": "positive"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[141, 146]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "YEAR",
"source": "{\"regextaggergroup_id\": 38, \"regextagger_id\": 289}",
"spans": "[[156, 161]]",
"str_val": "2010s"
},
{
"doc_path": "review_text",
"fact": "RATING",
"source": "{\"regextaggergroup_id\": 40, \"regextagger_id\": 293}",
"spans": "[[177, 189]]",
"str_val": "bad"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[15, 23]]",
"str_val": "negative"
}
]
},
{
"author": "dolan87",
"id": "38272",
"review_text": "Absolute garbage! Would not even recommend to my worst enemy. 1/10.",
"texta_facts": [
{
"doc_path": "review_text",
"fact": "RATING",
"source": "{\"regextaggergroup_id\": 40, \"regextagger_id\": 293}",
"spans": "[[62, 67]]",
"str_val": "bad"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[9, 16]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[18, 42]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[49, 54]]",
"str_val": "negative"
}
]
}
]
Tag Random Doc¶
Funktsioon „Tag Random Doc“ võimaldab loodud Regex Tagger Groupe testida kindlaks määratud andmestikust juhuslikult valitud dokumendi märgendamisega.
Parameetrid¶
Sisend¶
- indices:
Nimekiri Elasticsearchis indekseeritud andmestikest, millele mudeleid rakendada. NB! Andmestikud peavad olema vormindatud JSON sõnastikuna, milles võti = „name“ ja väärtus = <indeksi_nimi>, nt:
{"name": "my_dataset"}
- fields:
Nimekiri väljadest, millele valitud mudeleid rakendada.
Väljund¶
- tagger_group_id:
Märgendamiseks kasutatatud Regex Tagger Groupi ID.
- tagger_group_tag:
Märgendamiseks kasutatud Regex Tagger Groupi nimi (ehk Regex Tagger Groupi description väärtus).
- result:
Binaarväärtus, mis väljendab, kas dokumendile leiti valitud mudelitega märgendeid või mitte.
- document:
Juhuslikult valitud dokument.
- matches:
Leitud märgendid „texta_facts“ formaadis.
- fact:
Regex Tagger Groupi nimi (sama, mis parameetri tagger_group_tag väärtus).
- str_val:
Regex Taggeri mudeli nimi.
- doc_path:
Välja nimi, kust märgend tuvastati.
- spans:
Tuvastatud märgendi aktiveerinud mustri asukoht tekstis.
- source:
JSON string formaadis sõnastik võtmetega Regex Tagger Group ID ja Regex Tagger ID.
GUI¶
Juhusliku dokumendi märgendamiseks Regex Tagger Group mudeliga navigeeri „Models“ -> „Regex Tagger Groups“ nagu kujutatud joonisel Joonis 103. Vali mudel, mida märgendamiseks kasutada ning ava vastava mudeli valikmenüü vajutades mudeli rea lõpus olevale kolmele vertikaalsele punktile. Vali avanenud menüüst „Tag „Random Doc“ nagu kujutatud joonisel Joonis 117.
Joonis 117 „Tag Random Doc“ valikmenüüs¶
Nupule vajutamise tagajärjel avaneb uus aken pealkirjaga „Tag Random Doc“. Vali menüüst pealkirjaga „Indices“ andmestik(ud), mille seast juhuslik dokument valida ning menüüst pealkirjaga „Select Fields“ dokumendi väljad, mida märgendamiseks kasutada. Seejärel vajuta akna alumises paremas nurgas asuvale nupule „Tag“ (Joonis 118).

Joonis 118 „Tag Random Doc“ aken enne märgendamist.¶
Märgendamise tulemused kuvatakse samas aknas. Joonis Joonis 119 kujutab positiivset märgendamise tulemust (juhuslikult valitud dokumendist leiti valitud mudeliga märgendid). Joonis Joonis 120 kujutab negatiivset märgendamise tulemust (juhuslikult valitud dokumendist valitud mudeliga märgendeid ei tuvastatud).
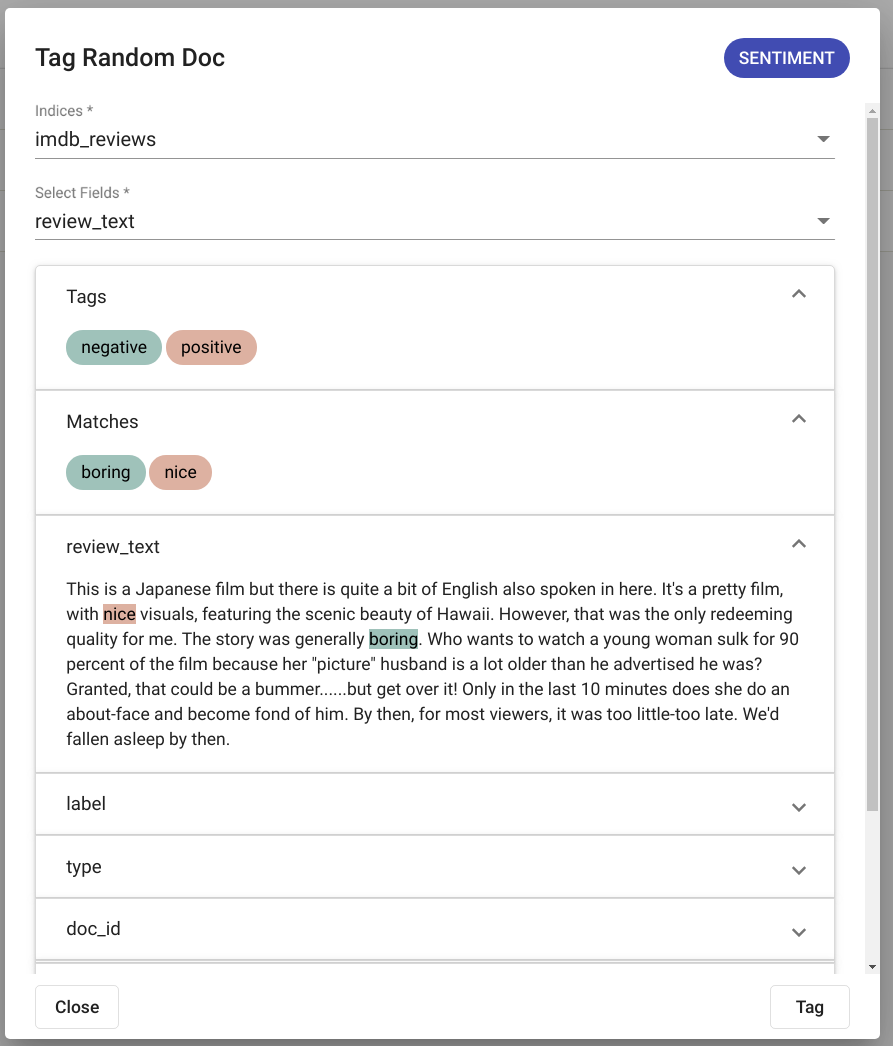
Joonis 119 „Tag Random Doc“ positiivne tulemus¶

Joonis 120 „Tag Random Doc“ negatiivne tulemus¶
PS! Dokumendi väljad, mida kasutaja märgendamiseks ei valinud või kust märgendeid ei leitud, on vaikimisi suletud. Soovi korral on neid võimalik aga avada klikkides nooleikoonil vastava välja sektsiooni lõpus (Joonis 121).
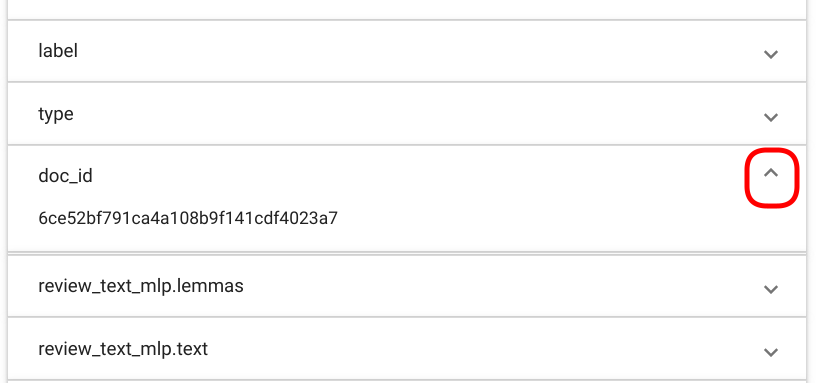
Joonis 121 „Tag Random Doc“ väljade avamine ja sulgemine.¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_tag_random_doc
Otspunkt /projects/{project_pk}/regex_tagger_groups/{id}/tag_random_doc/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/41/tag_random_doc/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"indices": [{"name": "imdb_reviews"}],
"fields": ["review_text"]
}'
Vastus:
{
"tagger_group_id": 41,
"tagger_group_tag": "SENTIMENT",
"result": true,
"matches": [
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "review_text",
"spans": "[[999, 1010]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "review_text",
"spans": "[[1119, 1130]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[433, 437]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[736, 743]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[1874, 1879]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
}
],
"document": {
"review_text": "Murder in Mesopotamia, I have always considered one of the better Poirot books, as it is very creepy and has an ingenious ending. There is no doubt that the TV adaptation is visually striking, with some lovely photography and a very haunting music score. As always David Suchet is impeccable as Hercule Poirot, the comedic highlight of the episode being Poirot's battle with a mosquito in the middle of the night, and Hugh Fraser is good as the rather naive Captain Hastings. The remainder of the cast turn in decent performances, but are careful not to overshadow the two leads, a danger in some Christie adaptations. Some of the episode was quite creepy, a juxtaposition of an episode as tragic as Five Little Pigs, an episode that I enjoyed a lot more than this one. What made it creepy in particular, putting aside the music was when Louise Leidner sees the ghostly face through the window. About the adaptation, it was fairly faithful to the book, but I will say that there were three things I didn't like. The main problem was the pacing, it is rather slow, and there are some scenes where very little happens. I didn't like the fact also that they made Joseph Mercado a murderer. In the book, I see him as a rather nervous character, but the intervention of the idea of making him a murderer, and under-developing that, made him a less appealing character, though I am glad they didn't miss his drug addiction. (I also noticed that the writers left out the fact that Mrs Mercado in the book falls into hysteria when she believes she is the murderer's next victim.) The other thing that wasn't so impressive was that I felt that it may have been more effective if the adaptation had been in the viewpoint of Amy Leatheran, like it was in the book, Amy somehow seemed less sensitive in the adaptation. On the whole, despite some misjudgements on the writers' behalf, I liked Murder in Mesopotamia. 7/10 Bethany Cox.",
"label": "positive",
"type": "train",
"doc_id": "73ff0a897bb84570ac5a0426a7f69b92"
}
}
Tag Text¶
Funktsioon „Tag Text“ võimaldab üksiku teksti märgendamist valitud Regex Tagger Groupi kuuluvate Regex Tagger mudelitega.
Parameetrid¶
Sisend¶
- text:
Märgendatav tekst.
Väljund¶
- tagger_group_id:
Märgendamiseks kasutatatud Regex Tagger Groupi ID.
- tagger_group_tag:
Märgendamiseks kasutatud Regex Tagger Groupi nimi (ehk Regex Tagger Groupi description väärtus).
- result:
Binaarväärtus, mis väljendab, kas dokumendile leiti valitud mudelitega märgendeid või mitte.
- text:
Sisendtekst.
- matches:
Leitud märgendid „texta_facts“ formaadis.
- fact:
Regex Tagger Groupi nimi (sama, mis parameetri tagger_group_tag väärtus).
- str_val:
Regex Taggeri mudeli nimi.
- doc_path:
Välja nimi, kust märgendid tuvastati. Antud juhul alati „text“.
- spans:
Tuvastatud märgendi aktiveerinud mustri asukoht tekstis.
- source:
JSON string formaadis sõnastik võtmetega Regex Tagger Group ID ja Regex Tagger ID.
GUI¶
Teksti märgendamiseks Regex Tagger Group mudeliga navigeeri „Models“ -> „Regex Tagger Groups“ nagu kujutatud joonisel Joonis 103. Vali mudel, mida märgendamiseks kasutada soovid ning ava valikmenüü vajutades kolmele vertikaalsele punktile valitud mudeli rea lõpus. Vali avanenud menüüst „Tag Text“ nagu kujutatud joonisel Joonis 122.
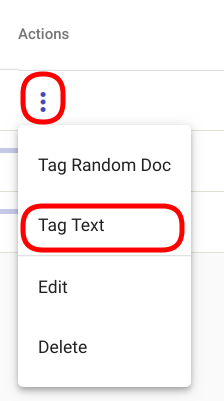
Joonis 122 „Tag Text“ valikmenüüs¶
Nupule vajutamise tagajärjel avaneb uus aken pealkirjaga „Tag Text“. Sisesta tekst, mida märgendada, ning vajuta akna alumises paremas nurgas asuvale nupule „Tag“ (Joonis 123).

Joonis 123 Teksti märgendamise aken „Tag Text“.¶
Tulemused kuvatakse samas aknas. Joonis Joonis 124 kujutab positiivset märgendamise tulemust (tekstist leiti valitud mudeliga märgendid) ja joonis Joonis 125 kujutab negatiivset märgendamise tulemust (tekstist valitud mudeliga märgendeid ei leitud).
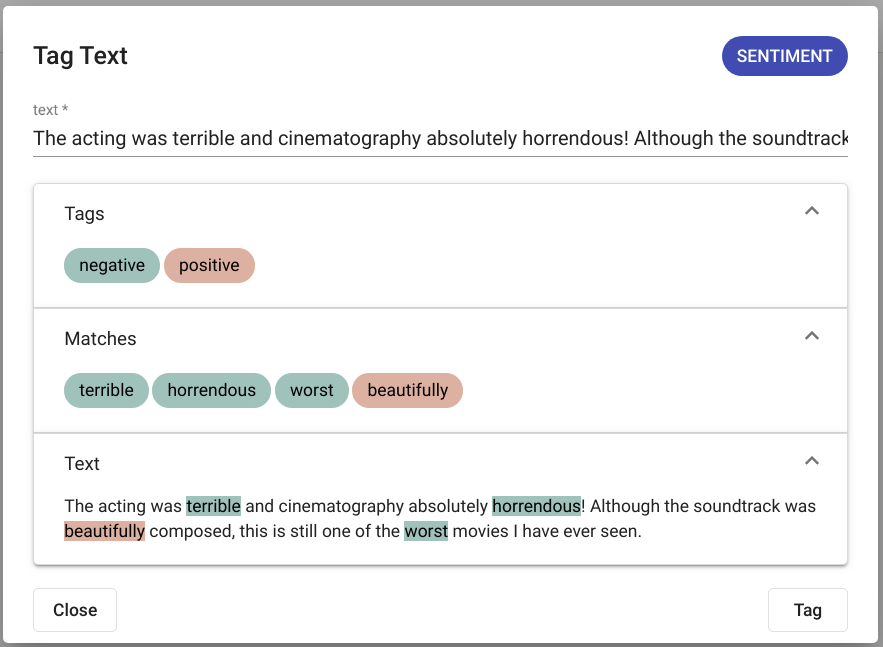
Joonis 124 „Tag Text“ positiivne tulemus¶

Joonis 125 „Tag Text“ negatiivne tulemus¶
API¶
Viide: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_tag_text
Otspunkt /projects/{project_pk}/regex_tagger_groups/{id}/tag_text/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/1/tag_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films I have ever seen."
}'
Vastus:
{
"tagger_group_id": 41,
"tagger_group_tag": "SENTIMENT",
"result": true,
"text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films I have ever seen.",
"matches": [
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[15, 23]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[54, 64]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[141, 146]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "text",
"spans": "[[94, 105]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
}
]
}