Regex Tagger¶
Regex Tagger on tööriist tekstide mustripõhiseks märgendamiseks regulaaravaldiste abil.
Märkus
Regex Tagger baseerub Pythoni regexi moodulil, mistõttu tuleks mustrite loomisel kasutada samuti Pythoni regulaaravaldiste süntaksit.
Loomine¶
Järgnev sektsioon katab kõik Regex Taggerite loomisega seonduva.Peatükis Parameetrid antakse ülevaade sisendparamteetritest; peatükis GUI antakse ülevaade Regex Taggerite loomisest graafilise kasutajaliidese kaudu; Peatükis API antakse ülevaade Regex Taggerite loomisest API kaudu.
Parameetrid¶
Järgnev peatükk annab ülevaate Regex Taggeri sisendparameetritest.
- description:
Regex Taggeri nimi, mida kasutatakse ühtlasi ka märgendina.
- lexicon:
Nimekiri leksikonikannetest, mida tekstist otsida.
Märkus
Leksikonikanded võivad olla tavalised sõna (nt. „kass“), fraasid (nt. „must kass“), või regulaaravaldised (nt. „d{2}-d{2}-d{4}“).
- counter_lexicon:
Nimekiri põhileksikonikandeid annulleerivatest sõnadest/fraasidest/regulaaravaldistest.
- operator:
Loogiline operatsioon leksikonikannete sidumiseks.
- Toetatud valikud:
- or:
positiivse tulemuse tagastamiseks peab tekstis leiduma vähemalt üks leksikonikannetest.
- and:
positiivne tulemust tagastatakse üksnes siis, kui tekstis esinevad kõik leksikonikanded. (NB! vaata ka parameetrit to required_words!)
- required_words:
Nõutud minimaalne leksikonikannete osakaal tekstis. Näiteks, kui meil onneljast sõnast koosnev leksikon ja parameeter „required_words“ = 1.0, siis tagastatakse positiivne tulemusüksnes juhul, kui kõik leksikonis leiduvat 4 sõna esinevad ka tekstis; kui aga parameeter „required_words“ = 0.5, piisab positiivse tulemuse jaoks üksnes poolte sõnade tekstis esinemisest.
Märkus
Parameetril on mõju üksnes juhul kui „operator“ = „and“
- match_type:
Leksikonikannete teksti sõnadele/fragmentidele sobitamise viis.
- Toetatud valikud:
- prefix:
Leksikonikanne peab esinema tekstis leiduva sõna/fraasi alguses, kuid sellele võib järgneda ka muid alfabeetilisi tähemärke. Näiteks tuvastatakse leksikonikanne „kass“ nii sõnadest „kass“ kui ka „kassid“, kuid mitte sõnast „karkass“.
- exact:
Leksikonikanne peab täielikult ühtima tekstis leiduva sõna/fraasiga. Näiteks tuvastatakse leksikonikanne „kass“ sõnast „kass“, kuid mitte sõnadest „kassid“ ega „karkass“
- subword:
Leksikonikanne peab esinema tekstis leiduvas sõna/fraasis, kuid nii selle ees kui ka järel võib olla ka teisi alfabeetilisi tähemärke.Näiteks tuvastatakse leksikonikanne „kass“ nii sõnadest „kass“, „kassid“ kui ka „karkass“.
- phrase_slop:
Lubatud maksimaalne leksikoniväliste sõnade arv iga leksikonikande sõnade vahel
- counter_slop:
Lubatud maksimaalne sõnade arv põhileksikonikannete ja annuleerivate leksikonikannete vahel, et annuleerival leksikonikandel mõju oleks.
- return_fuzzy_match:
Aktiveerituna tagastatakse terve sõna/fragment, kust leksikonikanne tuvastati.
- n_allowed_edits:
Lubatud maksimaalne tähemuudatuste arv tekstis leiduva sõna/fragmendi ning leksikonikande vahel (Levenshteini kaugus.“).
Märkus
Tähemuudatuseks loetakse ühte järgnevast:
tähe puudumine, nt. „kass“ -> „kas“
tähe lisamine nt. „kass“ -> „klass“
tähe asendamine nt. „kass“ -> „gass“
- ignore_case:
Aktiveerituna ignoreeritakse tõusutundlikkust.
- ignore punctuation:
Lause lõppu tähistavate tähemärkide esinemine leksikonikande sõnade vahel muudab tuvastatud kande kehtetuks; lause lõppu tähistavate tähemärkide esinemine põhileeksikonikande ning annuleeriva leksikonikande vahel, muudab annuleeriva leksikonikande mõju kehtetuks.
Märkus
Ignoreeritavate lauselõpumärkide hulka kuuluvad: [„.“, „!“, „?“]
Märkus
Ole antud parameetri kasutamisel ettevaatlik, kuna lauselõpumärgid tuvastatakse „naiivselt“ nimekirja alusel. See aga tähendab, et parameetri seatud piirang kehtib ka juhul kui tekstist tuvastatud nimekirja kuuluv märk vastavas kontekstis tegelikult lause lõppu ei tähista. Näiteks lauses „George R.R. Martin ja J.R.R. Tolkien läksid kalale“, loetakse lauselõpumärkide hulka kõik punktid, olgugi et nad seda tegelikult ei ole.
GUI¶
Uue Regex Taggeri mudeli loomiseks, navigeeri menüüribal „Models“ -> „Regex Taggers“ nagu kujutatud joonisel Joonis 81.
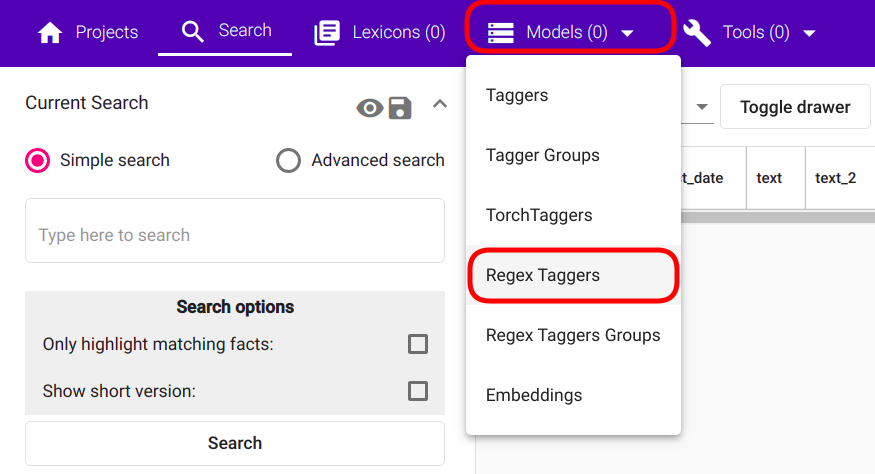
Joonis 81 Navigatsioon Regex Taggerini¶
Kui navigatsioon õnnestub, näed joonisega Joonis 82 sarnast paneeli, mille ülemises vasakus nurgas asub nupp nimega „Create“
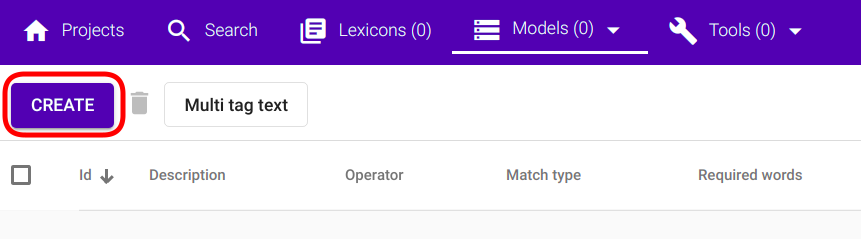
Joonis 82 Regex Taggeri loomisnupp¶
„Create“ nupu vajutamise järel avaneb hüpikaken tekstiga „New Regex Tagger“ (vt. Joonis 83).
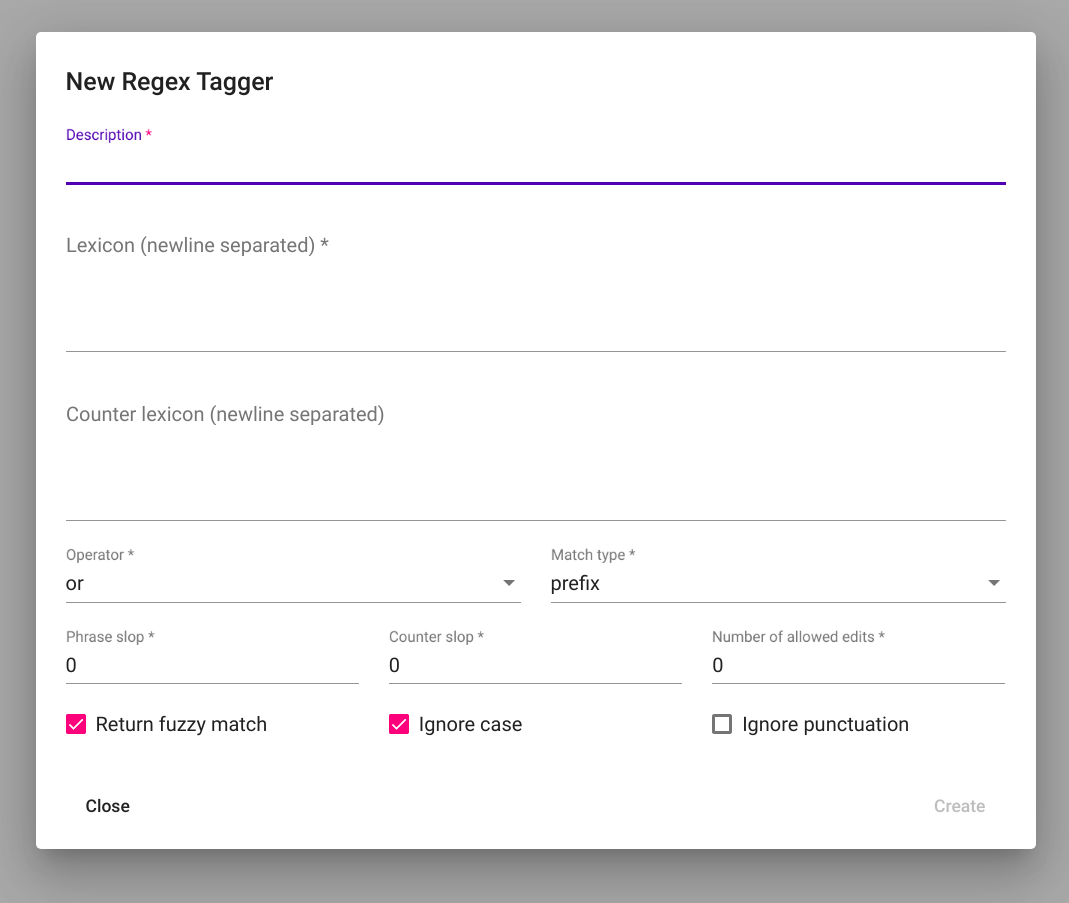
Joonis 83 Regex Taggeri loomisaken enne väljade täitmist¶
Täida nõutud väljad, muuda soovi korral vaikeparameetreid ning vajuta siis „`“Create“` nupule all paremas nurgas (vt. Joonis 84).
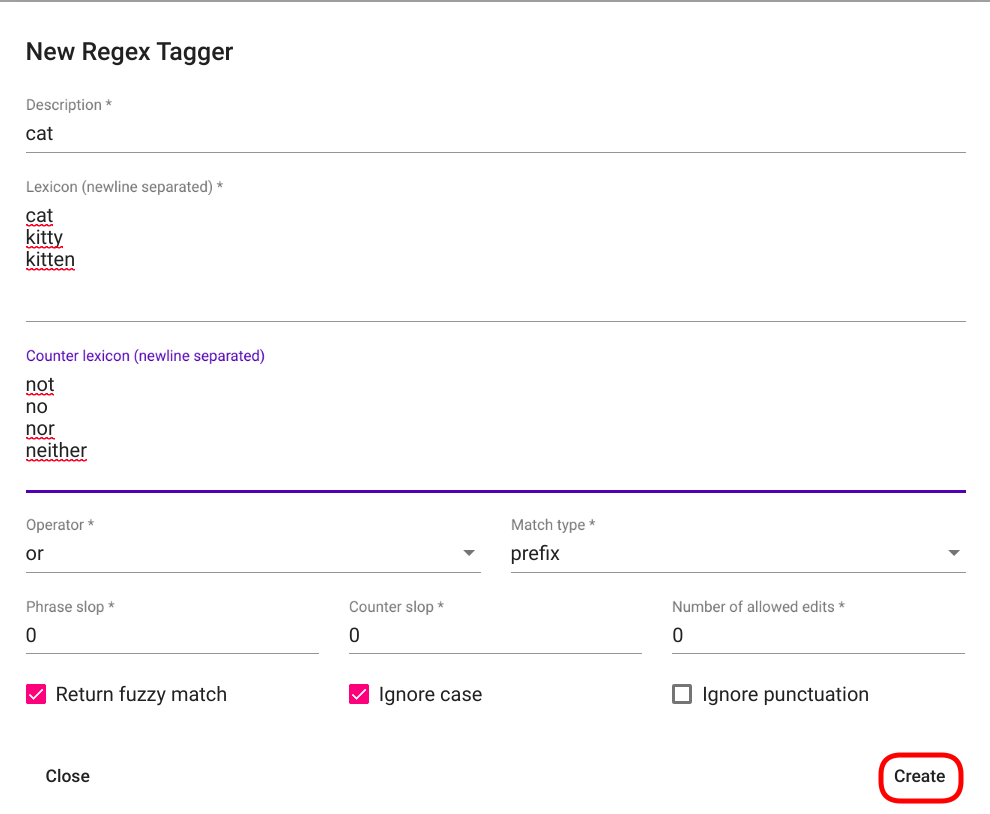
Joonis 84 Regex Taggeri loomisaken pärast väljade täitmist¶
Loodud Regex Tagger kuvatakse nüüd Regex Taggerite tabeli esimesel (või ainsal) real.

Joonis 85 Saadaolevate Regex Taggerite nimekiri¶
API¶
Otspunkt /projects/{project_pk}/regex_taggers/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/1/regex_taggers/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "cat",
"lexicon": ["cat", "kitten", "kitty"],
"counter_lexicon": ["no", "not", "nor", "neither"],
"operator": "or",
"match_type": "prefix",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": false
}'
Response:
{
"id": 131,
"url": "http://localhost:8000/api/v1/projects/1/regex_taggers/131/",
"author_username": "my_username",
"description": "cat",
"lexicon": [
"cat",
"kitten",
"kitty"
],
"counter_lexicon": [
"no",
"not",
"nor",
"neither"
],
"operator": "or",
"match_type": "prefix",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": false,
"tagger_groups": []
}
Kasutamine¶
Järgnevas sektsioonid kaetakse kõik Regex Taggeri funktsioonid. PS! Teatud funktsioone on võimalik rakendada üksnes läbi API.
Delete¶
Funktsioon „Delete“ võimaldab Regex Taggeri mudeleid kustutada.
GUI¶
Regex Taggeri mudeli kustutamiseks, navigeeri menüüribal „Models“ -> „Regex Taggers“ nagu kujutatud joonisel:numref:regex_tagger_navigation. Regex Taggeri kustutamiseks on kaks varianti:
Variant 1:
Vali mudel, mida soovid kustutada ning navigeeri kolme vertikaalse punktiga tähistatud valikute paneelile (Joonis 98) ning vali avanenud menüüst „Delete“ (Joonis 86)
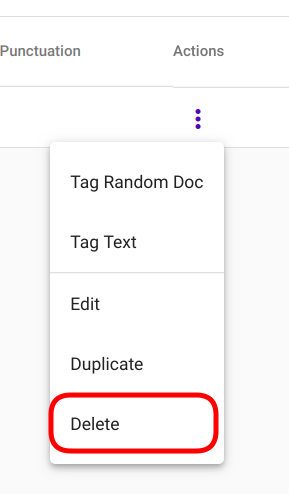
Joonis 86 Üksiku Regex Taggeri mudeli kustutamine¶
Variant 2:
Selekteeri kõik mudelid, mida soovid kustutada klikkides kastidele iga Regex Taggeri mudeli ees. (Joonis 87). Seejärel vajuta punasele prügikasti ikoonile „Create“ nupu kõrval lehekülje ülemises vasakus nurgas.
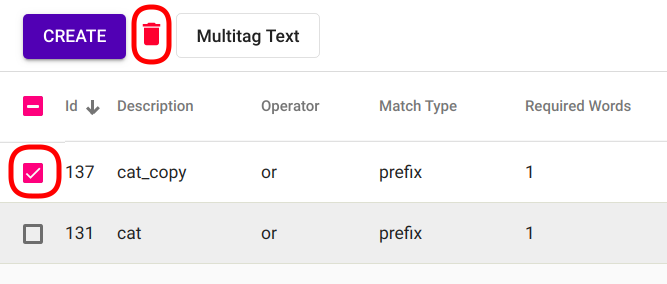
Joonis 87 Mitme Regex Taggeri mudeli samaaegne kustutamine¶
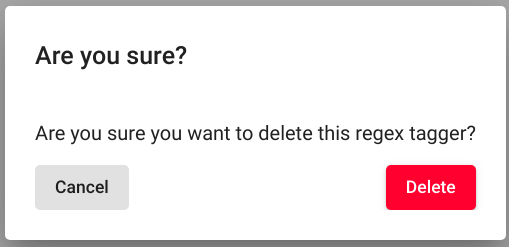
Joonis 88 Regex Taggeri mudeli(te) kustutamise kinnitus¶
Pärast emma-kumma variandi kõikide eelkirjeldatud sammude läbimist, kuvab kasutajaliides enne mudeli(te) lõplikku kustutamist kinnitusakent. Kustutamise protsessi lõpule viimiseks vajuta nupule „Delete“.
API¶
Otspunkt /projects/{project_pk}/regex_taggers/{id}/
Näide:
curl -X DELETE "http://localhost:8000/api/v1/projects/1/regex_taggers/131/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Duplicate¶
Funktsioon Duplicate võimaldab eksisteerivast Regex Taggeri mudelist koopia tegemist.
GUI¶
Regex Taggeri mudelist koopia tegemiseks, navigeeri „Models“ -> „Regex Taggers“ (Joonis 81). Vali mudel, millest soovid koopia teha ning ava valikute paneel liikudes kolmele vertikaalsele punktile mudelirea lõpus (Joonis 98).
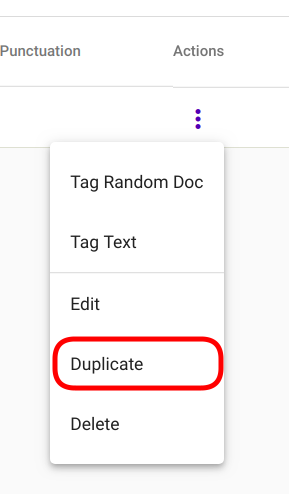
Joonis 89 Regex Taggeri mudeli duplikaadi tegemine.¶
Vali avanenud menüüst „Duplicate“ (Joonis 89).
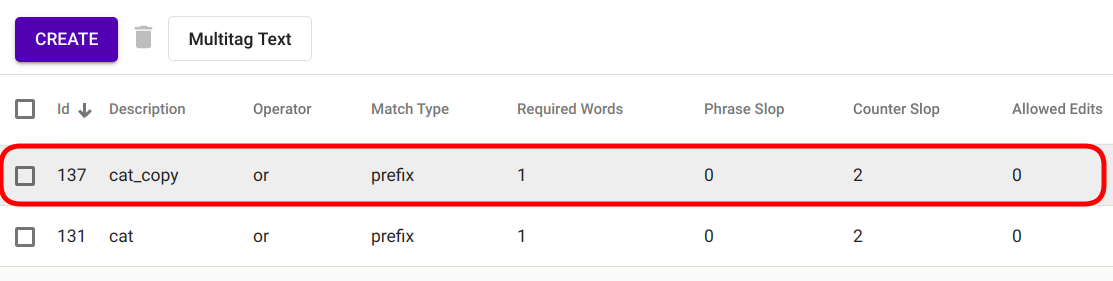
Joonis 90 Loodud duplikaat¶
Nupule vajutamise tagajärjel luuakse valitud Regex Taggeri duplikaat, mis ilmub koheselt ka Regex Taggeri mudelite nimekirja nimega „<lähtemudeli_nimi>_copy“ (Joonis 90).
API¶
Otspunkt /projects/{project_pk}/regex_taggers/{id}/duplicate/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/1/regex_taggers/131/duplicate/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{}'
Response:
{
"message": "Tagger duplicated successfully!",
"duplicate_id": 134
}
Edit¶
Funktsioon „Edit“ võimaldab Regex Taggeri mudeleid pärast loomist muuta.
GUI¶
Regex Taggeri mudeli muutmiseks, navigeeri „Models“ -> „Regex Taggers“ (Joonis 81). Vali mudel, mida muuta soovid ning ava valikute menüü klikkides kolmele vertikaalsele punktile valitud mudeli rea lõpus (Joonis 98).
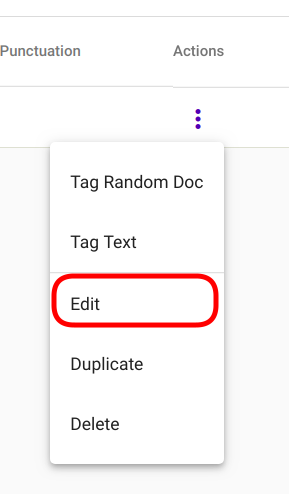
Joonis 91 Muuda Regex Taggerit¶
Vali avanenud menüüst „Edit“ (Joonis 91).
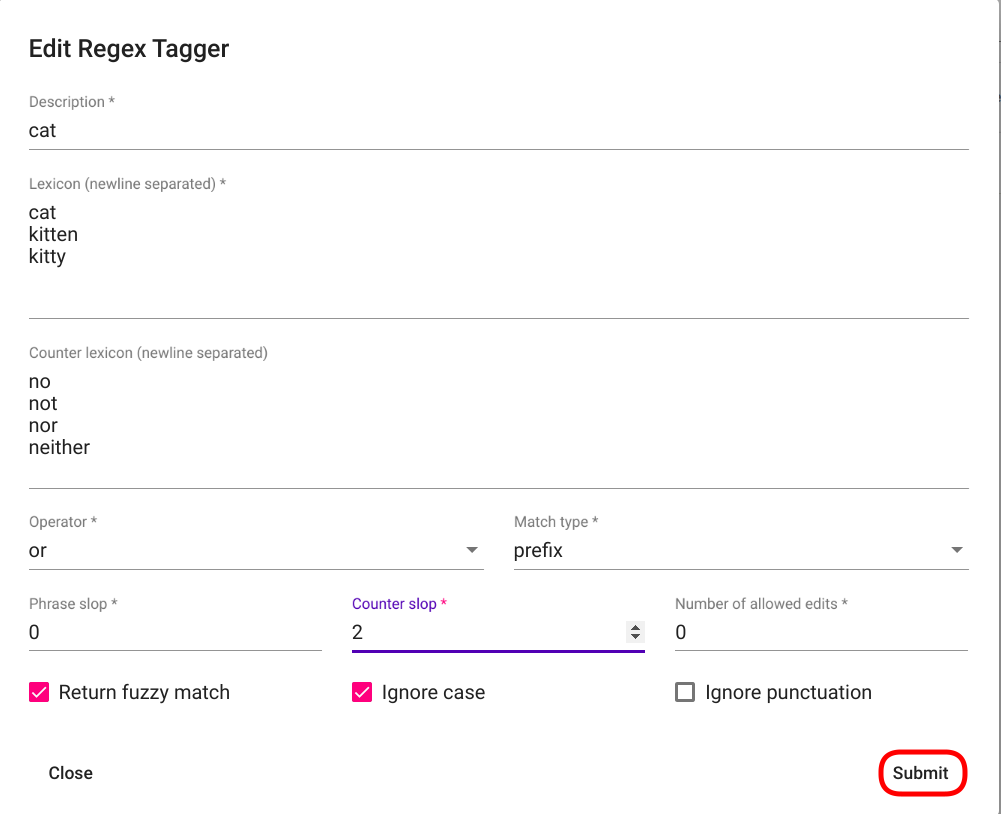
Joonis 92 Regex Taggeri muutmisaken¶
Valitud nupule klikkimise tagajärjel avaneb aken kirjaga „Edit Regex Tagger“. Tee soovitud muudatused ning vajuta akna alumises paremas nurgas asuvale nupule „Submit“ (Joonis 92).
API¶
Otspunkt /projects/{project_pk}/regex_taggers/{id}/
Näide:
curl -X PATCH "http://localhost:8000/api/v1/projects/1/regex_taggers/131/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"counter_slop": 2
}'
Response:
{
"id": 131,
"url": "https://rest-dev.texta.ee/api/v1/projects/1/regex_taggers/131/",
"author_username": "my_username",
"description": "cat",
"lexicon": [
"cat",
"kitten",
"kitty"
],
"counter_lexicon": [
"no",
"not",
"nor",
"neither"
],
"operator": "or",
"match_type": "prefix",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 2,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": false,
"tagger_groups": []
}
Tag Random Doc¶
Funktsioon „`“Tag Random Doc“` võimaldab märgendada juhusliku dokumendi valitud andmestikust.
GUI¶
Juhusliku dokumendi märgendamiseks Regex Taggeri mudeliga, navigeeri „Models“ -> „Regex Taggers“ nagu kujutatud joonisel Joonis 81. Vali mudel, mida märgendamiseks kasutada ning ava vastava mudeli valikmenüü vajutades mudeli rea lõpus olevale kolmele vertikaalsele punktile. Vali avanenud menüüst „Tag Random Doc“ nagu kujutatud joonisel Joonis 93.
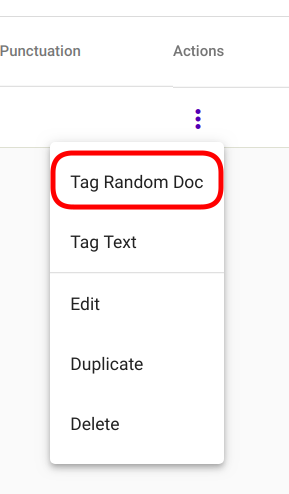
Joonis 93 „Tag Random Doc“ valikmenüüs¶
Nupule vajutamise tagajärjel avaneb uus aken pealkirjaga „Tag Random Doc“. Vali menüüst pealkirjaga „Indices“ andmestik(ud), mille seast juhuslik dokument valida ning menüüst pealkirjaga „Select Fields“ dokumendi väljad, mida märgendamiseks kasutada. Seejärel vajuta akna alumises paremas nurgas asuvale nupule „Tag“ (Joonis 94).

Joonis 94 „Tag Random Doc“ aken enne märgendamist.¶
Märgendamise tulemused kuvatakse samas aknas. Joonis Joonis 95 kujutab positiivset märgendamise tulemust (juhuslikult valitud dokumendist leiti valitud mudeliga märgendid). Joonis Joonis 96 kujutab negatiivset märgendamise tulemust (juhuslikult valitud dokumendist valitud mudeliga märgendeid ei tuvastatud).
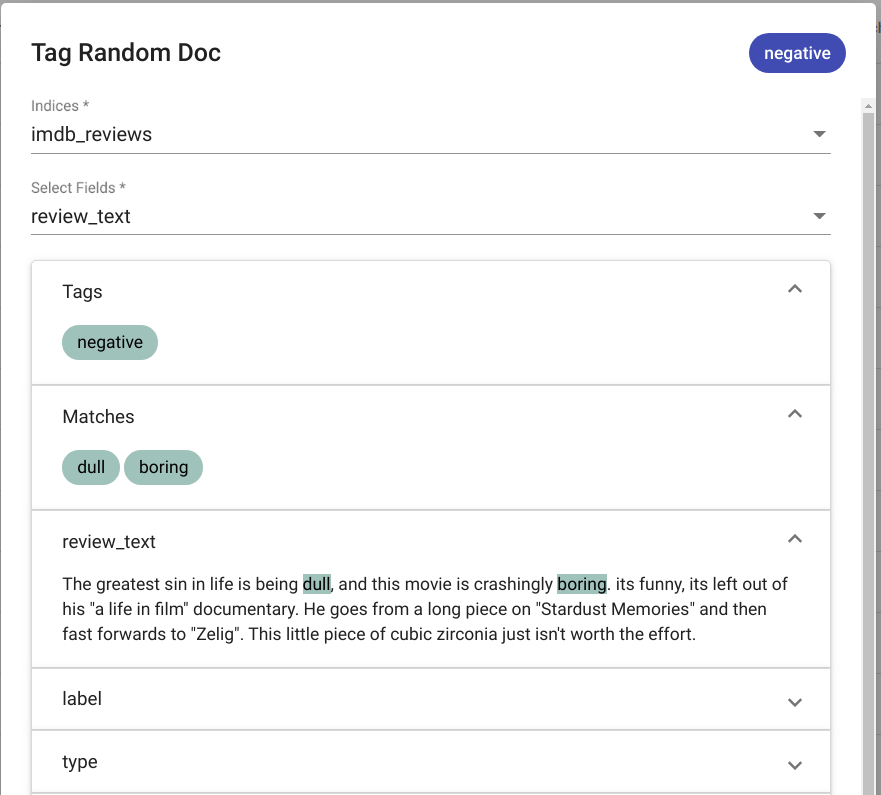
Joonis 95 „Tag Random Doc“ positiivne tulemus¶

Joonis 96 „Tag Random Doc“ negatiivne tulemus¶
PS! Dokumendi völjad, mida kasutaja märgendamiseks ei valinud või kust märgendeid ei leitud, on vaikimisi suletud. Soovi korral on neid võimalik aga avada klikkides nooleikoonil vastava välja sektsiooni lõpus (Joonis 97).
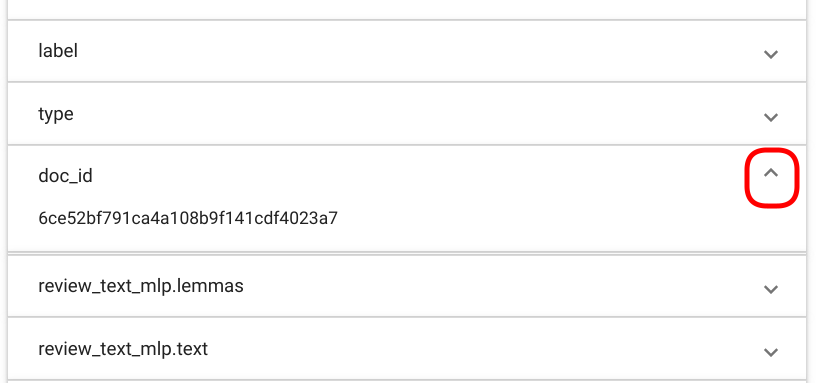
Joonis 97 „Tag Random Doc“ väljade avamine ja sulgemine.¶
API¶
Otspunkt /projects/{project_pk}/regex_taggers/{id}/tag_random_doc/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/1/regex_taggers/138/tag_random_doc/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"indices": [{"name": "imdb_reviews"}],
"fields": ["review_text"]
}'
Vastus (positiivse tulemuse korral)
{
"tagger_id": 138,
"tag": "positive",
"result": true,
"matches": [
{
"fact": "positive",
"str_val": "awesome",
"spans": "[[787, 794]]",
"doc_path": "review_text",
"source": "{\"regextagger_id\": 138}"
},
{
"fact": "positive",
"str_val": "good",
"spans": "[[911, 915]]",
"doc_path": "review_text",
"source": "{\"regextagger_id\": 138}"
},
{
"fact": "positive",
"str_val": "good",
"spans": "[[1032, 1036]]",
"doc_path": "review_text",
"source": "{\"regextagger_id\": 138}"
}
],
"document": {
"review_text": "I for one was very anxious to watch this movie. Though I knew it was going to be another type of movie in the style of Revenge of the Nerds, I was still impressed. There is plenty of truth to the fact of this type of learning and believe very strongly that it should be allowed in a \"new style of schooling\". Conventional teaching methods do not always teach students what they need to know or should know or want to know. This approach to teaching should be further sought out in true academic courses. While there still was too much of the partying scenes, it obviously had to be thrown in there - for Hollywood's sake of making a comedy about college...even though we all know that life isn't really like that by any means. A touch unbelievable, still funny and with a killer ending. Awesome ending. Crucial to the entire story and very surprising. Without the final scene, the movie would have been half as good. I liked this movie and it didn't have to have overly amounts of swearing or nudity or gross out jokes for it to be good. Great crew and cast, story and even the generic typecasting of the obligatory \"Hampton frat members\" was well done. American Pie 1, 2 3 and American Wedding or whatever clones it makes doers not measure up to this by 1/3. Far better than most comedies about first year College with no demeaning stupid jokes to make somebody throw up with. I liked it, even though it was simple...it was interesting and even had heart...my only regret for watching this movie is that it wasn't longer.",
"label": "positive",
"type": "test",
"doc_id": "efa2c957ce7c4588b91ef25ad2306390"
}
}
Vastus (negatiivse tulemuse korral)
{
"tagger_id": 138,
"tag": "positive",
"result": false,
"matches": [],
"document": {
"review_text": "Previous comments encouraged me to check this out when it showed up on TCM, but it was a severe disappointment. Lupe Valdez is great, but doesn't get enough screen time. Frank Morgan and Eugene Palette play familiar but promising characters, but the script leaves them stranded. The movie revolves around the ego of Lee Tracy's character, who is at best a self-centered, physically and verbally abusive jerk. The reactions of \"the public\" are poorly thought-out and unbelievable, making the \"shenanigans\" seem like contrivances of a bad writer. And it strains credulity that the Lupe Velez character could fall for him. The \"stinging one-liners\" mentioned in another review must be dependent on the observer, since I didn't even notice that an attempt was being made.",
"label": "negative",
"type": "train",
"doc_id": "6eec458e238d4cf58882b50e8df82855"
}
}
Tag Text¶
Funktsioon „Tag Text“ võimaldab Regex Taggeri mudeliga teksti märgendamist.
GUI¶
Teksti märgendamiseks navigeeri menüüribal „Models“ -> „Regex Taggers“ nagu kujutatud joonisel Joonis 81.
Joonis 98 Saadaolevate Regex Taggerite nimekiri¶
Vali mudel, mida märgendamiseks kasutada soovid ning ava valikmenüü klikkides kolmele vertikaalsele punktile rea lõpus (Joonis 98).
Joonis 99 Teksti märgendamine valikmenüüs¶
Vali avanenud menüüst „Tag Text“ (Joonis 99).

Joonis 100 Teksti märgendamise aken¶
Valitud nupule klikkimise tagajärjel avaneb uus aken kirjaga „Tag Text“. Sisesta tekst, mida soovid märgendada ning vajuta akna alumises paremas nurgas asuvale nupule „Tag“ (Joonis 100).
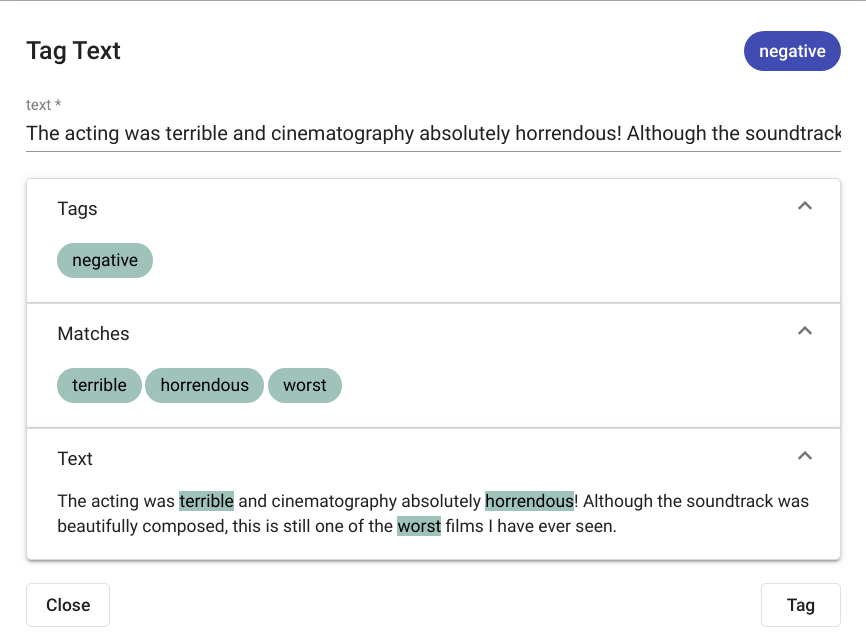
Joonis 101 Tekstist tuvastatud märgendid¶
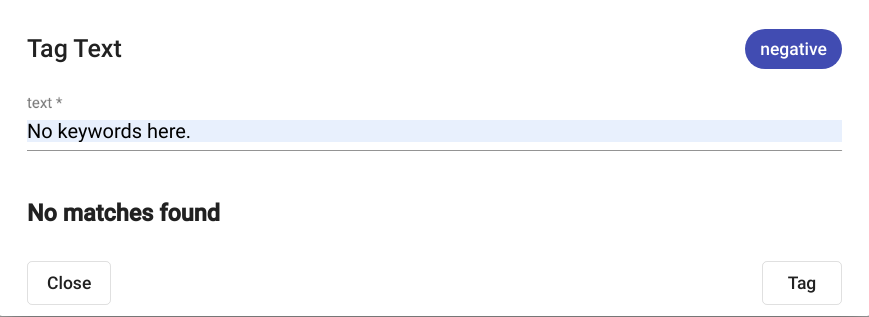
Joonis 102 Tekstist ei tuvastatud ühtegi märgendit¶
Märgendamise tulemused kuvatakse samas aknas (Joonis 101). Juhul kui tekstist valitud mudeliga märgendeid ei leita, kuvatakse aknas kiri „No matches found“ (Joonis 102).
API¶
Otspunkt /projects/{project_pk}/regex_taggers/{id}/tag_text/
Näide:
curl -X POST "http://localhost:8000/api/v1/projects/1/regex_taggers/131/tag_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "one cat, two dogs and seven kittens"
}'
Response:
{
"tagger_id": 131,
"tag": "cat",
"result": true,
"text": "one cat, two dogs and seven kittens",
"matches": [
{
"fact": "cat",
"str_val": "cat",
"spans": "[[4, 7]]",
"doc_path": "text",
"source": "{\"regextagger_id\": 131}"
},
{
"fact": "cat",
"str_val": "kittens",
"spans": "[[28, 35]]",
"doc_path": "text",
"source": "{\"regextagger_id\": 131}"
}
]
}