Regex Tagger Group¶
Regex Tagger Group allows combining multiple Regex Tagger models into a group which can then be used for tagging documents. The resulting tags are formatted as Texta Facts.
API Reference: http://localhost:8000/api/v1/redoc/#tag/projects-greater-regex_tagger_groups
Creation¶
Note
Regex Tagger Group can be created only if at least one Regex Tagger model exists.
Parameters¶
Input¶
- regex_taggers:
Regex Tagger models to be added to the group.
- description:
Name of the Regex Tagger Group, which will also be used as the name of the tag while tagging the documents. The name can be found in the following field after tagging:
API:
texta_facts.fact
GUI:
texta_facts.fact_name
Output¶
- id:
ID of the created Regex Tagger Group
- url:
URL of the created Regex Tagger Group
- regex_taggers:
IDs of Regex Taggers present in the group.
- author_username:
Creator of the Regex Tagger Group.
- task:
Celery task connected with the group.
- description:
Name of the Regex Tagger Group.
- tagger_info:
Parameters of each Regex Tagger present in the group.
GUI¶
For creating a new Regex Tagger Group, navigate to “Models” -> “Regex Tagger Groups” as seen in Fig. 103.
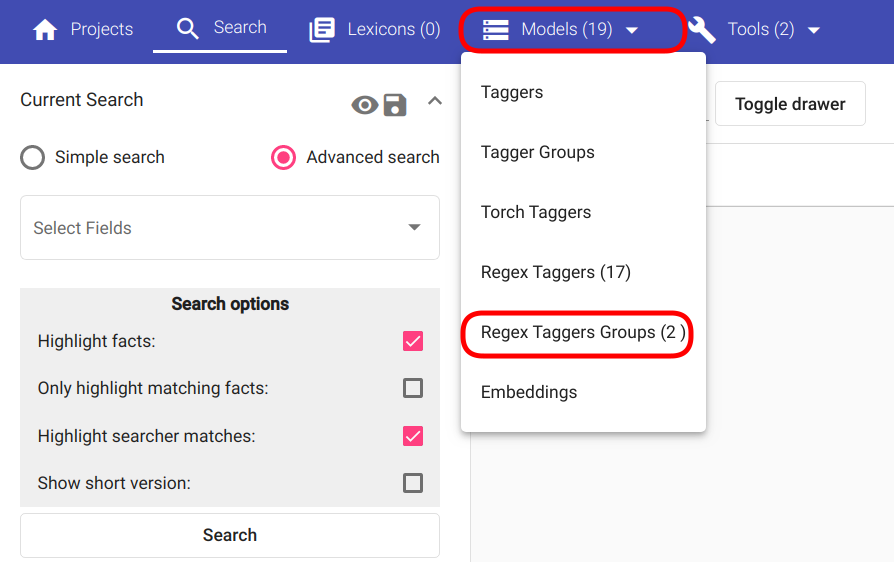
Fig. 103 “Regex Tagger Group” navigation¶
If the navigation is successful, you should see a panel similar to Fig. 104 with the “Create” button in the top left corner of the page.
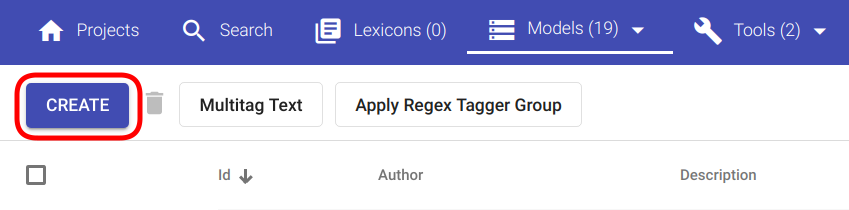
Fig. 104 “Regex Tagger Group” creation button¶
Clicking on the “Create” button opens a modal window with text “New Regex Tagger Group” as depicted in Fig. 105.
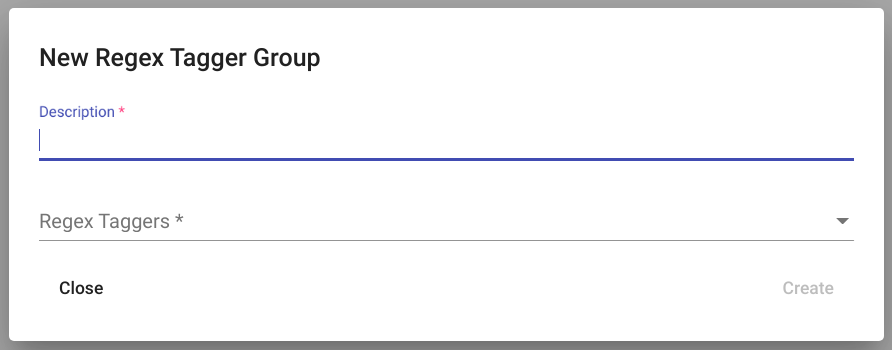
Fig. 105 Empty “Regex Tagger Group” creation view¶
Name the new Regex Tagger Group by filling in the field “Description” and select Regex Tagger models to add to the group from the Regex Taggers’ selection menu below. If finished, click on the “Create” button in the bottom right corner of the window (Fig. 106).
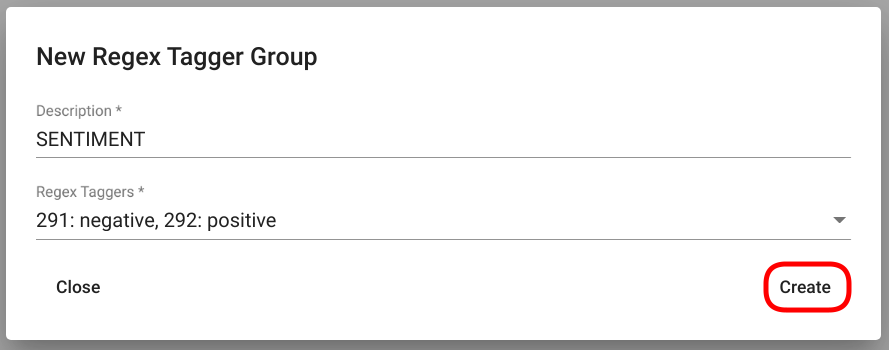
Fig. 106 Filled “Regex Tagger Group” creation view¶
The created Regex Tagger Group can now be seen as the first (or only, if no previous Regex Tagger Groups exist under the project) row in the table of Regex Tagger Groups (Fig. 107).

Fig. 107 List of Regex Tagger Groups.¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_create
Endpoint /projects/{project_pk}/regex_tagger_groups/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"regex_taggers": [293, 294, 295],
"description": "RATING"
}'
Response:
{
"id": 42,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/42/",
"regex_taggers": [
293,
294,
295
],
"author_username": "masula",
"task": null,
"description": "RATING",
"tagger_info": [
{
"id": 293,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/293/",
"author_username": "masula",
"description": "bad",
"lexicon": [
"\\W*[1-4]/10\\W*",
"\\W*[1-4] out of 10\\W*",
"\\W*[1-2]/5\\W*",
"\\W*[1-2] out of 5\\W*",
"\\W*[1-4]/10\\W*",
"\\W*[1-4] stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
},
{
"id": 294,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/294/",
"author_username": "masula",
"description": "average",
"lexicon": [
"\\W*[5-6]/10\\W*",
"\\W*[5-6] out of 10\\W*",
"\\W*[3]/5\\W*",
"\\W*[3] out of 5\\W*",
"\\W*[5-6]/10\\W*",
"\\W*[5-6] stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
},
{
"id": 295,
"url": "https://rest-dev.texta.ee/api/v1/projects/251/regex_tagger_groups/295/",
"author_username": "masula",
"description": "good",
"lexicon": [
"\\W*([7-9]|10)/10\\W*",
"\\W*([7-9]|10) out of 10\\W*",
"\\W*[4-5]/5\\W*",
"\\W*[4-5] out of 5\\W*",
"\\W*([7-9]|10)/10\\W*",
"\\W*([7-9]|10) stars"
],
"counter_lexicon": [
"who gave it"
],
"operator": "or",
"match_type": "exact",
"required_words": 1.0,
"phrase_slop": 0,
"counter_slop": 0,
"n_allowed_edits": 0,
"return_fuzzy_match": true,
"ignore_case": true,
"ignore_punctuation": true,
"tagger_groups": [
{
"tagger_group_id": 40,
"description": "RATING"
}
]
}
]
}
Usage¶
Apply Tagger Group¶
Function “Apply Tagger Group” enables applying Regex Tagger Group to one or many datasets indexed in Elasticsearch. Results are added to the field “texta_facts” accordingly:
RegexTaggerGroup.description -> texta_fact.fact (API) / texta_fact.fact_name (GUI)
RegexTagger.description -> texta_fact.str_val / texta_fact.fact_value (GUI)
Parameters¶
- description:
Name of the application task.
- indices:
List of Elasticsearch indices (datasets) onto which the selected models are applied. NB! Indices should be formatted as dicts, where key = “name” and value = <index_name>, e.g:
{"name": "my_dataset"}
- fields:
List of fields onto which the selected models are applied.
- query:
Specified Elasticsearch Search query.
- bulk_size:
Number of documents processed in one batch.
- max_chunk_bytes:
TODO
- regex_tagger_groups:
Regex Tagger Groups to apply.
Note
Only supported in GUI.
GUI¶
For applying one or multiple Regex Tagger Group(s) to a dataset indexed in Elasticsearch, navigate to “Models” -> “Regex Tagger Groups” as seen in Fig. 103. Click on the button “Apply Regex Tagger Group” as seen in Fig. 108.

Fig. 108 “Apply Regex Tagger Group” button¶
Clicking on the button opens a new modal window with the title “Apply Regex Tagger Group to indices”. Fill the required fields (see also: application parameters). PS! Leave the field “Query” empty if you wish to apply the models to all of the documents in the selected dataset(s). If finished, click on the button “Apply” in the bottom right corner of the panel (Fig. 109).
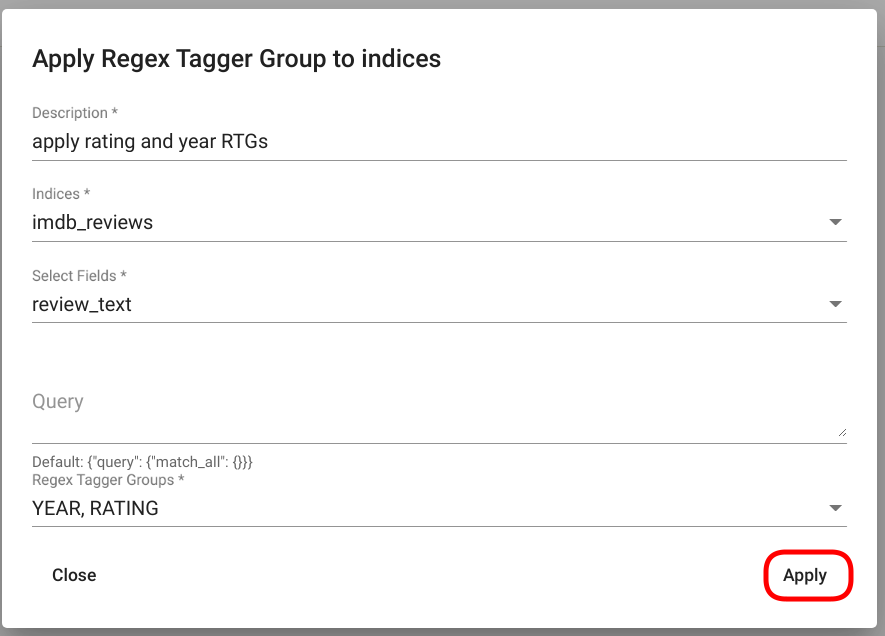
Fig. 109 “Apply Regex Tagger Group” window¶
If the application task creation was successful, the Task status of the selected Regex Tagger Group models should now be “created” or “running” as seen in Fig. 110.
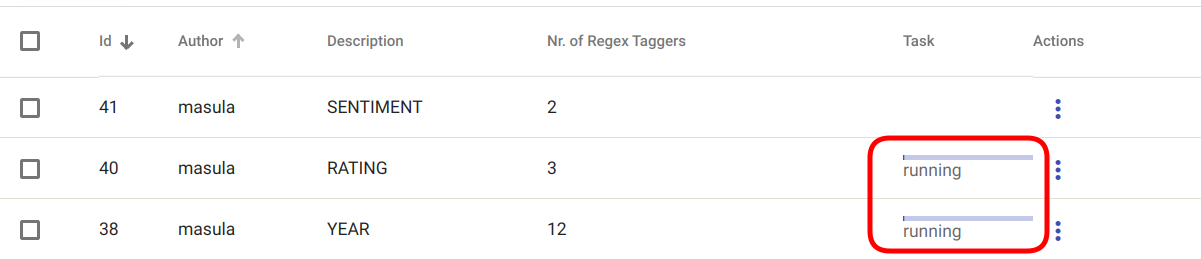
Fig. 110 “Apply Regex Tagger Group” task has started¶
If the application process is finished, you can now browse the results in Search (Fig. 111). The created tags can be found from the field “texta_facts”.

Fig. 111 “Apply Regex Tagger Group” output in Search.¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_apply_tagger_group
Endpoint /projects/{project_pk}/regex_tagger_groups/{id}/apply_tagger_group/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/apply_tagger_group/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "apply my regex tagger group",
"indices": [{"name": "imdb_reviews"}],
"fields": ["review_text"],
"bulk_size": 100
}'
Response:
{
"message": "Started process of applying RegexTaggerGroup with id: 40"
}
Delete¶
Function “Delete” allows deleting existing Regex Tagger Groups.
Note
Deleting a Regex Tagger Group does NOT delete Regex Tagger models belonging to the group.
GUI¶
For deleting a Regex Tagger Group through GUI, navigate to “Models” -> “Regex Tagger Groups” as seen in Fig. 103. There are two options for deleting a Regex Tagger Group:
Option 1:
Select the Regex Tagger Group you wish to delete by navigating to the options panel denoted with three vertical dots and select the option “Delete” from the selection menu as seen in Fig. 112.
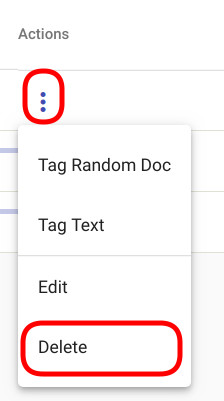
Fig. 112 Delete a single Regex Tagger Group¶
Option 2:
Select the model(s) you wish to delete by clicking on the selection boxes in front of the Regex Tagger Groups(s). If all the models you wish to delete are selected, click on the red recycle bin icon beside the “Create” button in the top left corner of the page. (Fig. 113).
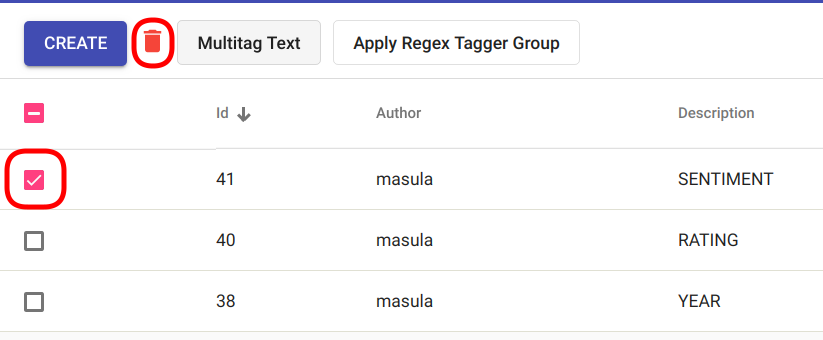
Fig. 113 Bulk delete Regex Tagger Group(s)¶
After following all the previously described steps (for either of the two options), the interface should now ask your confirmation for finishing the process (Fig. 114). Agree by clicking on the button “Delete”.
Fig. 114 Delete Regex Tagger Group(s) confirmation¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_delete
Endpoint /projects/{project_pk}/regex_tagger_groups/{id}/
Example:
curl -X DELETE "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Edit¶
GUI¶
For editing an existing Regex Tagger Group, select the Regex Tagger Group you wish to edit and navigate to the options panel by clicking on the three vertical dots at the end of the Regex Tagger Group row. Select the option “Edit” as seen in Fig. 115.
Fig. 115 Regex Tagger Group -> Edit¶
Clicking on the option opens a new modal window with text “Edit Regex Tagger Group”. Make your modifications and click on the “Apply” button in the bottom right corner of the modal window for finishing the process (Fig. 116.)

Fig. 116 “Edit Regex Tagger Group” window¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_update
Endpoint /projects/{project_pk}/regex_tagger_groups/{id}/
Example:
curl -X PATCH "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/40/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "UPDATED_REGEX_TAGGER_MODEL_NAME"
}'
Multitag Docs¶
Function “Multitag Docs” enables tagging one or many documents with multiple Regex Tagger Group models at once. Results are added to the field “texta_facts” accordingly:
RegexTaggerGroup.description -> texta_fact.fact (API) / texta_fact.fact_name (GUI)
RegexTagger.description -> texta_fact.str_val (API) / texta_fact.fact_value (GUI)
RegexTagger.match.spans -> texta_fact.spans
field -> texta_fact.doc_path
Parameters¶
Input¶
- docs:
Documents to tag as a list of JSON dicts, e.g:
[ { "doc_id": 24, "title": "some title", "text": "foo bar" }, { "doc_id": 56, "title": "some other title", "text": "bar foo" } ]
- fields:
List of fields onto which the selected models are applied.
- tagger_groups:
List of the Regex Tagger Group ID-s to use for tagging.
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_multitag_docs
Endpoint /projects/{project_pk}/regex_tagger_groups/multitag_docs/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/multitag_docs/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"docs": [
{
"review_text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films of 2015. I will give it 2 out of 10.",
"id": "27252",
"author": "jster976"
},
{
"review_text": "Absolute garbage! Would not even recommend to my worst enemy. 1/10.",
"id": "38272",
"author": "dolan87"
}
],
"fields": ["review_text"],
"tagger_groups": [38, 40, 41]
}'
Response:
[
{
"author": "jster976",
"id": "27252",
"review_text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films of 2015. I will give it 2 out of 10.",
"texta_facts": [
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[54, 64]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}",
"spans": "[[94, 105]]",
"str_val": "positive"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[141, 146]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "YEAR",
"source": "{\"regextaggergroup_id\": 38, \"regextagger_id\": 289}",
"spans": "[[156, 161]]",
"str_val": "2010s"
},
{
"doc_path": "review_text",
"fact": "RATING",
"source": "{\"regextaggergroup_id\": 40, \"regextagger_id\": 293}",
"spans": "[[177, 189]]",
"str_val": "bad"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[15, 23]]",
"str_val": "negative"
}
]
},
{
"author": "dolan87",
"id": "38272",
"review_text": "Absolute garbage! Would not even recommend to my worst enemy. 1/10.",
"texta_facts": [
{
"doc_path": "review_text",
"fact": "RATING",
"source": "{\"regextaggergroup_id\": 40, \"regextagger_id\": 293}",
"spans": "[[62, 67]]",
"str_val": "bad"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[9, 16]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[18, 42]]",
"str_val": "negative"
},
{
"doc_path": "review_text",
"fact": "SENTIMENT",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}",
"spans": "[[49, 54]]",
"str_val": "negative"
}
]
}
]
Tag Random Doc¶
Function “Tag Random Doc” provides support for testing a Regex Tagger Group on a randomly selected document from a certain predefined dataset.
Parameters¶
Input¶
- indices:
List of Elasticsearch indices (dataset) onto which the selected models are applied. NB! Indices should be formatted as dicts, where key = “name” and value = <index_name>, e.g:
{"name": "my_dataset"}
- fields:
List of fields onto which the selected models are applied.
Output¶
- tagger_group_id:
ID of the Regex Tagger Group used for tagging.
- tagger_group_tag:
Name of the Regex Tagger Group used for tagging, i.e. Regex Tagger Group description.
- result:
Boolean value indicating if any matches were detected.
- document:
The randomly selected document.
- matches:
Detected matches in the “texta_facts” format.
- fact:
Name of the Regex Tagger Group (same as corresponding tagger_group_tag).
- str_val:
Name of the Regex Tagger model.
- doc_path:
Name of the field from where the match was detected.
- spans:
Position of the detected match in the input field.
- source:
Dict given as JSON string containing corresponding Regex Tagger Group ID and Regex Tagger ID.
GUI¶
For tagging a random document with an existing Regex Tagger Group model, navigate to “Models” -> “Regex Tagger Groups” as seen in Fig. 103. Select the model you wish to use and navigate to the options panel denoted with three vertical dots. Select the option “Tag Random Doc” from the selection menu as seen in Fig. 117.
Fig. 117 “Tag Random Doc” option in the selection menu¶
Selecting the option opens a new modal window with the title “Tag Random Doc”. Select the index or indices you wish to use from the “Indices” selection menu displayed in the window after clicking on the corresponding section and select the field(s) you wish to use from the “Select Fields” selection menu below. If finished, click on the button “Tag” in the bottom right corner of the panel (Fig. 118).

Fig. 118 Regex Tagger Group “Tag Random Doc” window.¶
The results are displayed in the same modal window as seen in Fig. 119 if any matches were detected. If no matches where found, the text “No matches found” is displayed as seen in Fig. 120.
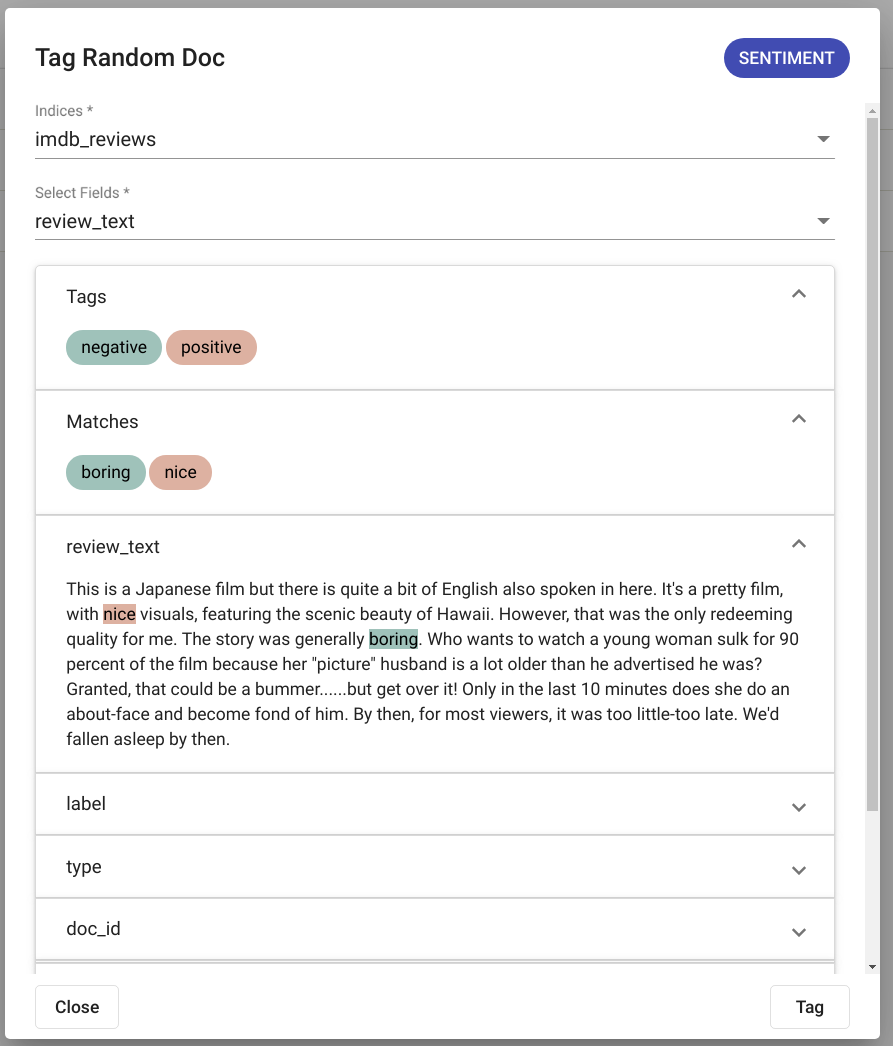
Fig. 119 “Tag Random Doc” positive output¶

Fig. 120 “Tag Random Doc” negative output¶
PS! The fields in the document not selected by the user and/or not containing any matches are by default collapsed, but you can view their content by clicking on the arrow icon at the end of each field (Fig. 121.)
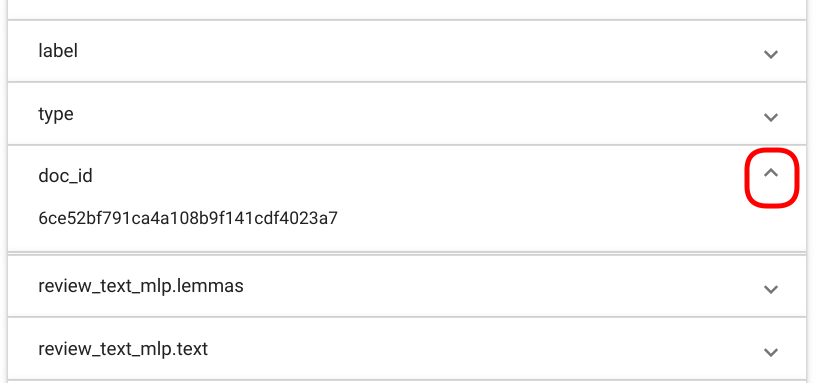
Fig. 121 “Tag Random Doc” collapsing/uncollapsing fields.¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_tag_random_doc
Endpoint /projects/{project_pk}/regex_tagger_groups/{id}/tag_random_doc/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/41/tag_random_doc/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"indices": [{"name": "imdb_reviews"}],
"fields": ["review_text"]
}'
Response:
{
"tagger_group_id": 41,
"tagger_group_tag": "SENTIMENT",
"result": true,
"matches": [
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "review_text",
"spans": "[[999, 1010]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "review_text",
"spans": "[[1119, 1130]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[433, 437]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[736, 743]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "review_text",
"spans": "[[1874, 1879]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
}
],
"document": {
"review_text": "Murder in Mesopotamia, I have always considered one of the better Poirot books, as it is very creepy and has an ingenious ending. There is no doubt that the TV adaptation is visually striking, with some lovely photography and a very haunting music score. As always David Suchet is impeccable as Hercule Poirot, the comedic highlight of the episode being Poirot's battle with a mosquito in the middle of the night, and Hugh Fraser is good as the rather naive Captain Hastings. The remainder of the cast turn in decent performances, but are careful not to overshadow the two leads, a danger in some Christie adaptations. Some of the episode was quite creepy, a juxtaposition of an episode as tragic as Five Little Pigs, an episode that I enjoyed a lot more than this one. What made it creepy in particular, putting aside the music was when Louise Leidner sees the ghostly face through the window. About the adaptation, it was fairly faithful to the book, but I will say that there were three things I didn't like. The main problem was the pacing, it is rather slow, and there are some scenes where very little happens. I didn't like the fact also that they made Joseph Mercado a murderer. In the book, I see him as a rather nervous character, but the intervention of the idea of making him a murderer, and under-developing that, made him a less appealing character, though I am glad they didn't miss his drug addiction. (I also noticed that the writers left out the fact that Mrs Mercado in the book falls into hysteria when she believes she is the murderer's next victim.) The other thing that wasn't so impressive was that I felt that it may have been more effective if the adaptation had been in the viewpoint of Amy Leatheran, like it was in the book, Amy somehow seemed less sensitive in the adaptation. On the whole, despite some misjudgements on the writers' behalf, I liked Murder in Mesopotamia. 7/10 Bethany Cox.",
"label": "positive",
"type": "train",
"doc_id": "73ff0a897bb84570ac5a0426a7f69b92"
}
}
Tag Text¶
Function “Tag Text” enables tagging a single text with a selected Regex Tagger Group by applying all the models belonging in the group to the selected text.
Parameters¶
Input¶
- text:
Text to tag.
Output¶
- tagger_group_id:
ID of the Regex Tagger Group used for tagging.
- tagger_group_tag:
Name of the Regex Tagger Group used for tagging, i.e. Regex Tagger Group description.
- result:
Boolean value indicating if any matches were detected.
- text:
Input text.
- matches:
Detected matches in the “texta_facts” format.
- fact:
Name of the Regex Tagger Group (same as corresponding tagger_group_tag).
- str_val:
Name of the Regex Tagger model.
- doc_path:
Name of the field from where the match was detected. Always “text” in the current endpoint.
- spans:
Position of the detected match in the text.
- source:
Dict given as JSON string containing corresponding Regex Tagger Group ID and Regex Tagger ID.
GUI¶
For tagging a text with an existing Regex Tagger Group model, navigate to “Models” -> “Regex Tagger Groups” as seen in Fig. 103. Select the model you wish to use and navigate to the options panel denoted with three vertical dots. Select option “Tag Text” from the selection menu as seen in Fig. 122.
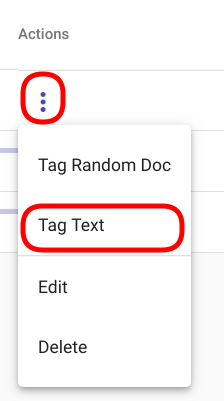
Fig. 122 “Tag Text” option in the selection menu¶
Selecting the option opens a new modal window with the title “Tag Text”. Insert the text you wish to tag and click on the button “Tag” in the bottom right corner of the panel (Fig. 123).

Fig. 123 Regex Tagger Group “Tag Text” window.¶
The results are displayed in the same modal window as seen in Fig. 124, if any matches where detected. If no matches where found, the text “No matches found” is displayed as seen in Fig. 125.
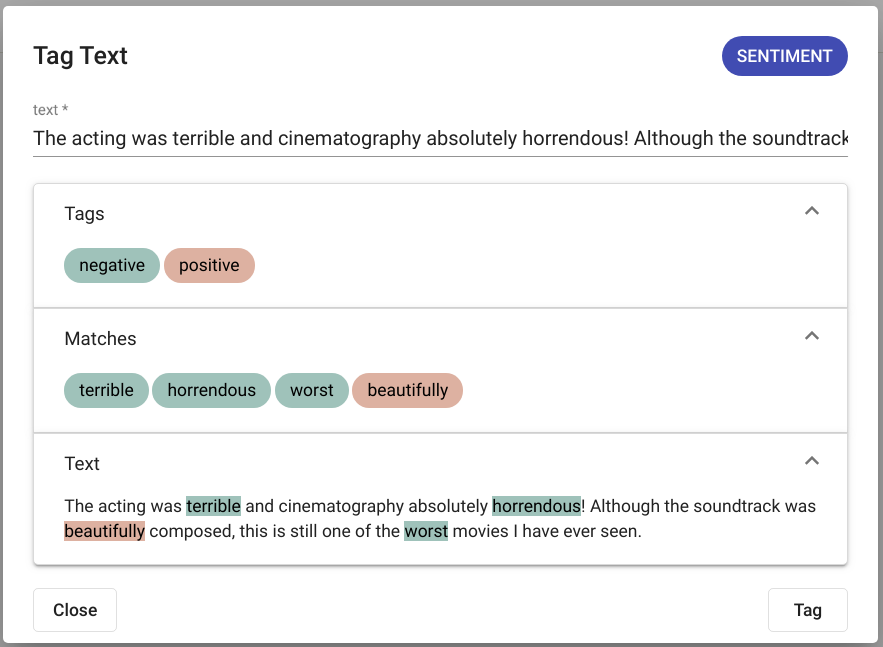
Fig. 124 “Tag Text” positive output¶

Fig. 125 “Tag Text” negative output¶
API¶
Reference: http://localhost:8000/api/v1/redoc/#operation/projects_regex_tagger_groups_tag_text
Endpoint /projects/{project_pk}/regex_tagger_groups/{id}/tag_text/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/11/regex_tagger_groups/1/tag_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films I have ever seen."
}'
Response:
{
"tagger_group_id": 41,
"tagger_group_tag": "SENTIMENT",
"result": true,
"text": "The acting was terrible and cinematography absolutely horrendous! Although the soundtrack was beautifully composed, this is still one of the worst films I have ever seen.",
"matches": [
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[15, 23]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[54, 64]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "negative",
"doc_path": "text",
"spans": "[[141, 146]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 291}"
},
{
"fact": "SENTIMENT",
"str_val": "positive",
"doc_path": "text",
"spans": "[[94, 105]]",
"source": "{\"regextaggergroup_id\": 41, \"regextagger_id\": 292}"
}
]
}