Tagger¶
Tagger kasutab masinõpet ning salvestatud otsinguid.
Märkus
- Kuidas erinevad Tagger ja Tagger Groups?
Üks mudel ennustab, kas tekst on positiivne (True) või negatiivne (False). St, kas tekst saab märgendi või mitte. Tagger treenib vaid ühe mudeli ning ennustab, kas tekst on sarnane sellele andmestikule / salvestatud otsingule, millel see treeniti. Tagger Group treenib mitu mudelit korraga. St, see võib ennustada mitu märgendit korraga. Tagger Group treenib end faktide põhjal. Meil võib olla mitu erinevat väärtust ühe kindla fakti all ning iga väärtuse kohta (kui sellel väärtusel on piisavalt kõrge sagedus (Minimum sample size)) treenitakse eraldi mudel.
Loomine¶
Parameetrid¶
- description
Tagger mudeli ja märgendi, millega hakatakse dokumente märgendama, nimi.
- indices
Indeksid, mille peal mudel õppima hakkab
- fields:
Väljad, mis lähevad mudeli sisendiks. Kui valitakse rohkem kui üks väli, kleepitakse need väljad lihtsalt enne treenimisprotsessi kokku. Ka ühest väljast piisab. Tavaliselt eelistatakse lemmatiseeritud tekste, eritieriti morfoloogiliselt rikaste keelte puhul, kuna see tõstab mõnede sõnade sagedust (söödud, sõi and sääb saavad kõik oma lemmaks vormi sööma ja neid käsitletakse ühe sõnana).
- query:
Searcheri otsing sellele andmestikule, mille peal hakatakse treenima.Tühi Query võtab sisendiks kogu andmestiku aktiivses projektis. Soovitud sisendiks võib valida ka salvestatud otsingu. Salvestatud otsing on märgendajale positiivsete näidete kogum - hiljem märgendab mudel sellele otsingukogumile sarnaseid andmeid.
- embedding:
Eelnevalt sama andmestiku peal treenitud sõnavektorid.
- vectorizer:
Hashing Vectorizer, Count Vectorizer, Tfldf Vectorizer - loe nende kohta rohkem siit.
- classifier:
- maximum sample size:
Maksimaalne näidiste hulk ühe klassi kohta limiteerib treeningandmestiku suurust.
- minimum_sample_size:
Minimum number of positive examples.
- negative multiplier:
Negatiivse korrutaja abil saab muuta negatiivsete näidete suhet positiivsetega treeningandmestikus.
- fact_name:
Fact name used for multiclass classification. NB! The selected fact should have at least two unique values!
- pos_label:
Fact value used as the positive label while calculating various evaluation scores like precision, recall and f1.
Märkus
Defining this parameter is necessary only, if:
a) param fact name is defined and
b) the defined fact name has exactly two unique values.
- balance:
Whether or not to balance the classes for multiclass classification. If this parameter is enabled, the examples for each class are sampled with repetitions until their size is either equal to
a) the size of the class with the largest number of examples (param balance to max limit is disabled) or
b) the max limit defined with parameter maximum sample size (param balance to max limit is enabled).Märkus
This parameter has effect only if param fact name is defined.
- balance_to_max_limit:
If enabled, the examples for each class are sampled with repetitions until the limit set with param maximum sample size is reached.
- stopwords:
List of words ignored while training the classifier.
- ignore_numbers:
If enabled, all the numbers in the text are ignored as possible features. It is advisable to enable this parameters, unless you know for certain that the numbers in the text convey meaningful information.
- snowball_language:
The language used by the Snowball stemmer.
Märkus
This param should be specified only if:
a) you wish to stem the data before feeding it to the classification models and
b) the input data is monolingual (otherwise it is advisable to use the param detect language instead).
- detect_lang:
If enabled, the language of each document is detected to select an appropriate stemmer.
Märkus
This should be selected only if:
a) you wish to stem the data before feeding it to the classification models and
b) the input data is multilingual (otherwise it is advisable to use the param snowball language instead).
- scoring_function:
Specifies the score used while selecting the best model with k-fold cross-validation. Available options are:
„precision“
„recall“
„f1_score“
„accuracy“
„jaccard“
- score_threshold:
Elasticsearch score threshold for filtering out irrelevant examples. All examples below first document’s score * score threshold are ignored. Float between 0 and 1. Default: 0.0
GUI¶
Uut Tagger mudelit saab luua vajutades üleval vasakul olevat ‚+CREATE‘ nuppu. Seejärel vali parameetrid ning vajuta „Create“-nuppu (vajadusel keri natukene all).Nüüd on järele jäänud treeningprotsessi järgmine ja Taggeri tulemuste vaatamine.
Märkus
LinearSVC võib anda errorit, kui salvestatud otsingus on liiga vähe andmeid.
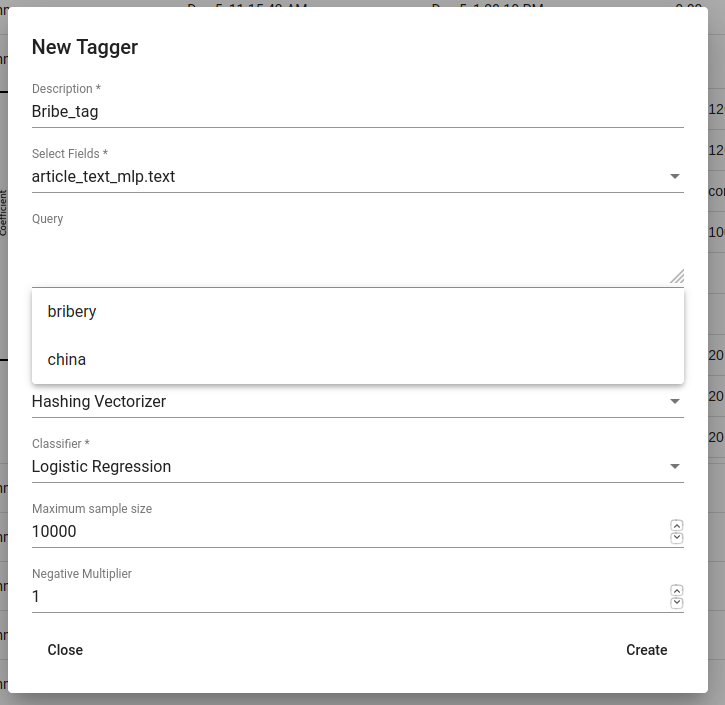
Joonis 65 Bribe_tag tagger-i loomine¶
Iga uue Tagger mudeli progressi saab jälgida tabelis, mis on Task-i all. Sellele reale vajutamine kuvab kogu treenimisinfo - kui kaua treenimine aega võttis, kui edukas mudel oli. Meeldetuletusena:
Recall ehk saagis on õigesti positiivseks märgendatute ja kõigi positiivsete elementide suhe.
Precision is the ratio of correctly labeled positives among all instances that got a positive label.
F1-skoor on nende kahe harmooniline keskmine ning peaks olema informatiivsem, eriti just tasakaalust väljas oleva andmestiku puhul.
Kolm täpikest Actions-i all avab lisategevuste nimekirja.
Tabeli vaates saame valida mitut mudelit korraga ja kustutada need, kasutades prügikasti nupukest +CREATE nupukese kõrval üleval vasakul. Mitme mudeli seast saab õiget otsida nende kirjelduse või task status-e kaudu. Kui mudeleid on palju, saad vahetada kuvamislehekülge üleval paremal.
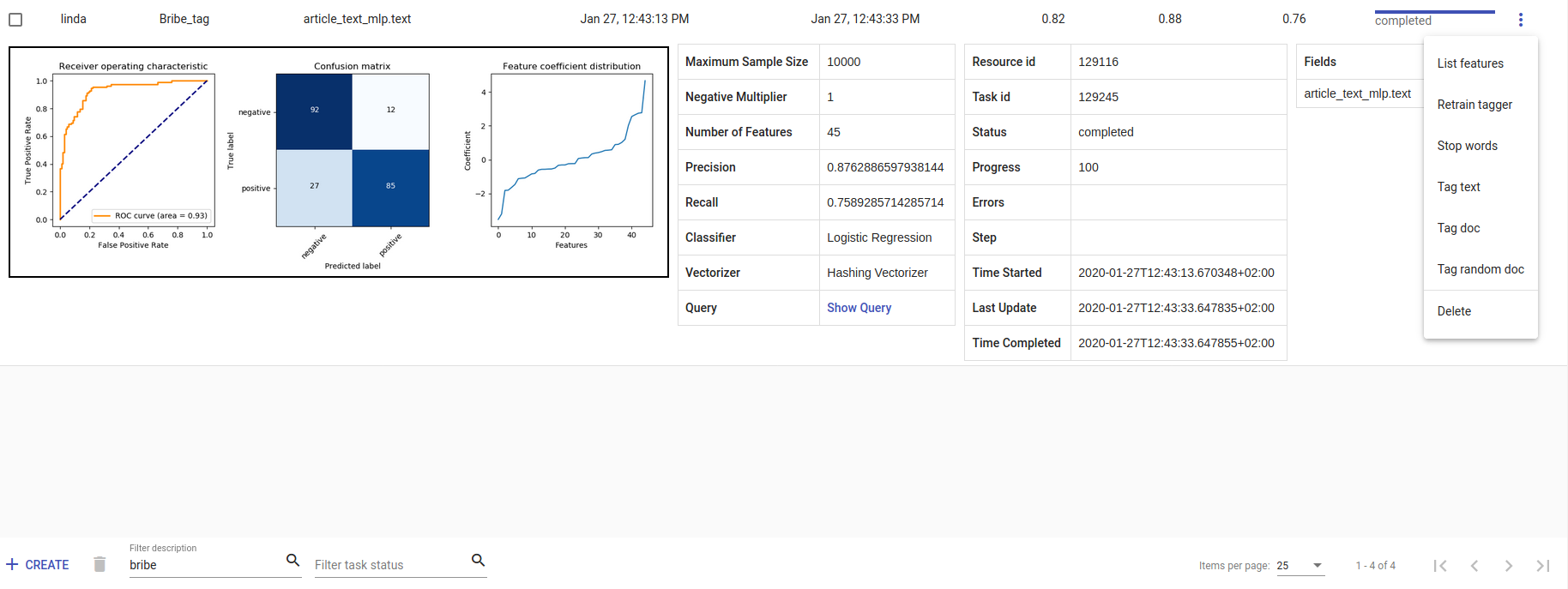
Joonis 66 Bribe_tag tagger¶
API¶
Otspunkt (endpoint): /projects/{project_pk}/taggers/
Näidis:
curl -X POST "http://localhost:8000/api/v1/projects/11/taggers/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "My tagger",
"fields": ["comment_content_lemmas"],
"vectorizer": "Hashing Vectorizer",
"classifier": "Logistic Regression",
"indices": [{"name": "texta_test_index"}],
"stop_words": "",
"maximum_sample_size": 10000,
"score_threshold": 0.0,
"negative_multiplier": 1,
}'
Otspunkt (endpoint): /projects/{project_pk}/taggers/
Kasutus¶
List features¶
List features väljastab sõnatunnused ja nende koefitsiendid, mida mudel kasutas. Töötab mudelitega, mis kasutasid Count Vectorizer-it või Tfldf Vectorizer-it, kuna nende väljund on kuvatav.
Otspunkt (endpoint): /projects/{project_pk}/taggers/{id}/tag_text/
Stop words¶
Stop words on stopp-sõnade lisamiseks. Stopp-sõnad on sõnad, mida mudel ei arvesta, kui ta otsib vihjeid sarnasuste kohta. Arukas on lisada nimekirja kõige sagedasemad sõnad nagu olema, mina, sees, kõrvalt. Sõnad tuleb eraldada tühikuga (‘ ‚).

Joonis 67 Adding stop words¶
Otspunkt (endpoint): /projects/{project_pk}/taggers/{id}/tag_text/
Tag text¶
Tag text aitab hõlpsasti kontrollida, kuidas mudel töötab. Sellele vajutades avaneb aken. Aknasse saab kleepida/kirjutada teksti, valida selle lemmatiseerimine (vajalik, kui mudel on treenitud lemmatiseeritud tekstil) ning seejärel see ‚postitada‘ (vajuta Post-nuppu). ‚Postitamine‘ väljastab tulemuse (True, kui antud tekst saab vastava täägi, ja False, kui ei saa) ja ennustuse tõenäosuse (probability). Tõenäosus näitab, kui kindel on antud mudel oma ennustuses.
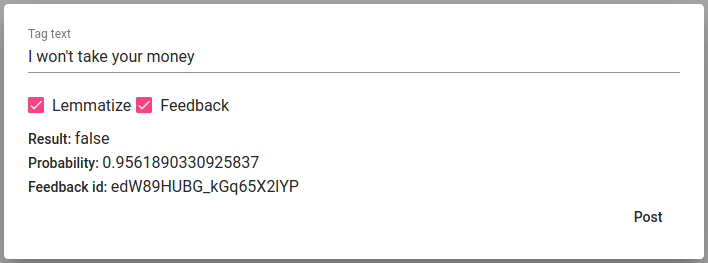
Joonis 68 Tagging a random written/pasted text¶
Otspunkt (endpoint): /projects/{project_pk}/taggers/{id}/tag_text/
Näidis:
curl -X POST "http://localhost:8000/api/v1/projects/11/taggers/2/tag_text/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"text": "mis su nimi on?",
"lemmatize": true
}'
Vastus:
{
"tag":"My tagger",
"probability":0.9898217973842874,
"tagger_id":2,
"result":true
}
Tag doc¶
Tag doc on sarnane Tag text-ile, ainult et sisend on JSON-formaadis.
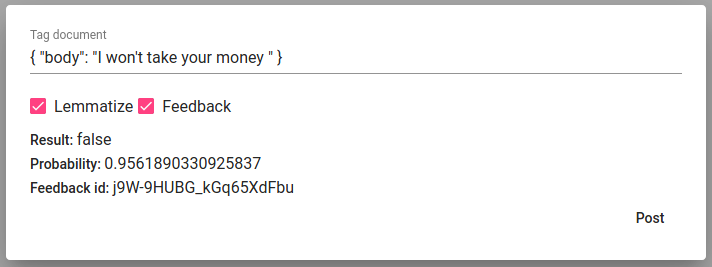
Joonis 69 Tagging a random written/pasted text in json format¶
Otspunkt (endpoint): /projects/{project_pk}/taggers/{id}/tag_text/
Tag random doc¶
Tag random doc võtab suvalise dokumendi andmestikust, väljastab selle ja tagastab tulemuse ja vastavasse klassi kuulumise tõenäosuse.
Otspunkt (endpoint): /projects/{project_pk}/taggers/{id}/tag_text/
Edit¶
Edit on kirjelduse (description) muutmiseks.
Retrain tagger¶
Retrain tagger treenib kogu Tagger mudeli samade parameetritega uuesti. See on kasulik, kui andmestik muutub või juurde on tulnud uusi stopp-sõnu.
Delete¶
Delete kustutab mudeli.