Evaluator¶
Evaluator is a tool for evaluating labels predicted with classification or entity extractor models. To use the evaluator, your dataset should contain both true and predicted labels formatted as Texta Facts.
Creation¶
Parameters¶
Input parameters¶
The following section gives an overview of Evaluator’s input parameters.
- description:
Name of the Evaluator model.
- indices:
List of Elasticsearch indices containing the tags (formatted as texta facts) to evaluate. NB! Indices should be formatted as list of dicts, where key = „name“ and value = <index_name>, e.g:
[{"name": "my_dataset"}]
- true_fact_name:
Name of the fact containing the actual label of the document (e.g. „TAG“).
- predicted_fact_name:
Name of the fact containing the predicted label of the document (e.g. „PREDICTED_TAG“).
- true_fact_value:
Value of the fact containing the actual label of the document (e.g. „sports“). NB! Only necessary for binary classification and should be left empty for mutliclass/multilabel classification.
- predicted_fact_value:
Value of the fact containing the predicted label of the document (e.g. „literature“). NB! Only necessary for binary classification and should be left empty for mutliclass/multilabel classification.
- average_function:
Sklearn averaging function used while evaluating the results. Available options are:
macro- Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.micro- Calculate metrics globally by counting the total true positives, false negatives and false positives.weighted- Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters macro to account for label imbalance; it can result in an F-score that is not between precision and recall.binary- Only report results for the class specified by pos_label. NB! Only applicable for binary classification.samples- Calculate metrics for each instance, and find their average. NB! Only applicable for multiclass/multilabel classification.
- add_individual_results:
Whether to save individual results for each label separately in addition to the overall (averaged) results. NB! Only applicable for multiclass/multilabel classification.
Märkus
It is generally advisable to enable it for getting a better understanding of the models. However, one should be careful if the number of unique labels is very high (>10 000) as it will make the evaluation process slower and might lead to memory issues.
- scroll_size:
Indicates how many documents are processed per one scroll.
- es_timeout:
After how many minutes of processing one batch of documents (n documents in batch = scroll_size) Elasticsearch throws a timeout and the processing is suspended.
Output parameters¶
- n_true_classes:
Number of true classes.
- n_predicted_classes:
Number of predicted classes.
- n_total_classes:
Number of true and predicted classes combined (as a union).
- document_count:
Number of evaluated documents.
- evaluation_type:
Indicates whether the labelset under the evaluation was binary (type = „binary“) or multilabel/multiclass (type = „multilabel“).
- score_after_scroll:
Binary field indicating whether the scores were calculated for each batch separately and the final result was retrieved by averaging the batch scores (i.e. if the value for this parameter has been set to true, the results might imprecise). The value of this parameter depends on the number of documents to evaluate (
document_count), the total size of the label set (n_total_classes) and the amount of available memory- scores_imprecise:
Indicates whether the calculated scores are precise or not. The value for this parameter is directly derived from the values of score_after_scroll and average_function as for some average functions calculating scores after each scroll has an effect while for others it doesn’t.
- precision:
- recall:
- f1_score:
- accuracy:
- plot:
Confusion matrix.
Märkus
Confusion matrix is generated only if the number of classes is <= 30 as the plot gets too big and hard to interpret with more than 30 classes.
GUI¶
For creating a new Evaluator task, navigate to „Tools“ -> „Evaluator“. Click on the button „CREATE“ in the upper left corner of the page.
After clicking on the button, a new Evaluator creation window is opened. Fill the required fields and modify the parameters you wish to change, then click on the button „Create“ in the bottom right corner of the window Joonis 29. A new row containing the information about the created Evaluator should now appear in the list of all Evaluators with a status „created“, „training“, or „completed“ (if not, try refreshing the page).
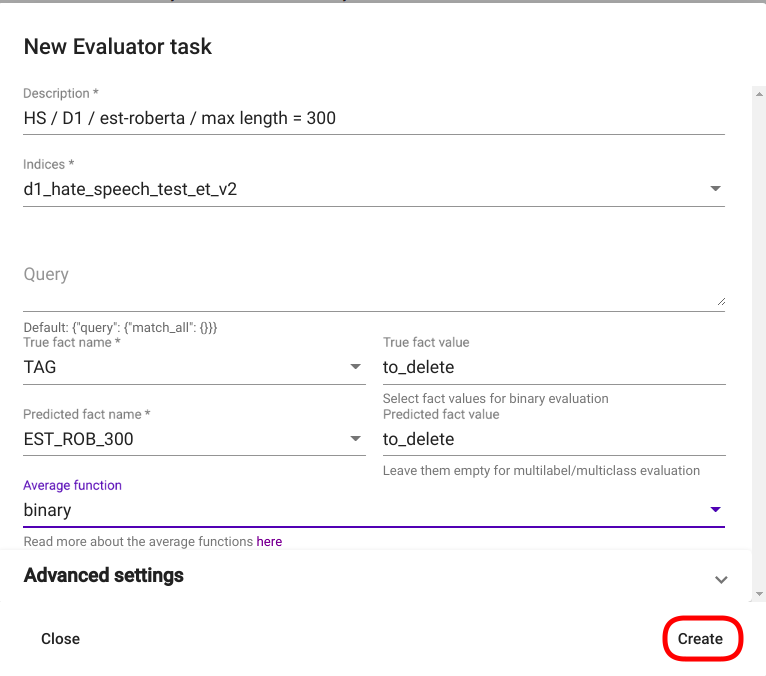
Joonis 29 Evaluator creation window¶
After the evaluation task in finished (task status = „completed“), you can see the results and various output parameters by clicking on the row (Joonis 30 and Joonis 31).
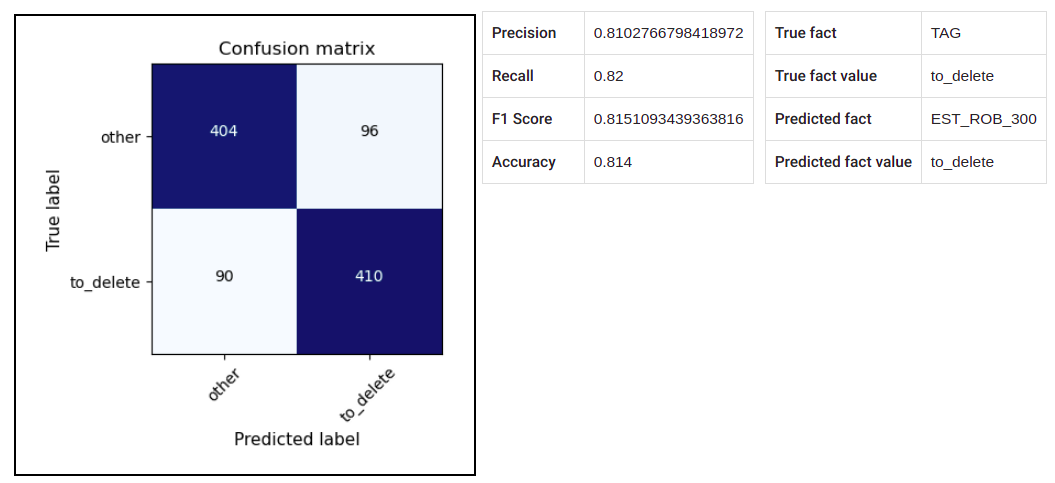
Joonis 30 Evaluator output (1)¶
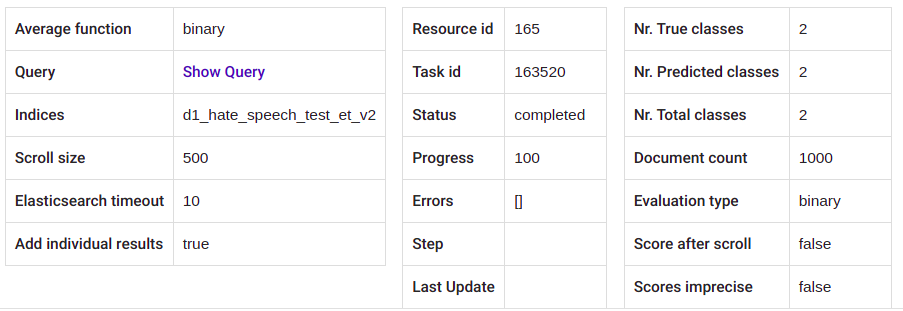
Joonis 31 Evaluator output (2)¶
API¶
Endpoint /projects/{project_pk}/evaluators/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/evaluators/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"description": "HS / D1 / est-roberta / max length = 300",
"indices": [{"name": "d1_hate_speech_test_et_v2"}],
"true_fact": "TAG",
"predicted_fact": "EST_ROB_300",
"true_fact_value": "to_delete",
"predicted_fact_value": "to_delete",
"average_function": "binary"
}'
Response:
{
"url": "https://rest-dev.texta.ee/api/v1/projects/1/evaluators/165/",
"author_username": "test_user",
"id": 165,
"description": "HS / D1 / est-roberta / max length = 300",
"indices": [
{
"id": 1758,
"is_open": true,
"url": "https://rest-dev.texta.ee/api/v2/elastic/index/1758/",
"name": "d1_hate_speech_test_et_v2",
"description": "",
"added_by": "test_user",
"test": false,
"source": "",
"client": "",
"domain": "comments",
"created_at": "2021-05-07T10:42:36.598000+03:00"
}
],
"query": "{\"query\": {\"match_all\": {}}}",
"true_fact": "TAG",
"predicted_fact": "EST_ROB_300",
"true_fact_value": "to_delete",
"predicted_fact_value": "to_delete",
"average_function": "binary",
"f1_score": 0.8151093439363816,
"precision": 0.8102766798418972,
"recall": 0.82,
"accuracy": 0.814,
"confusion_matrix": "[[404, 96], [90, 410]]",
"n_true_classes": 2,
"n_predicted_classes": 2,
"n_total_classes": 2,
"evaluation_type": "binary",
"scroll_size": 500,
"es_timeout": 10,
"scores_imprecise": false,
"score_after_scroll": false,
"document_count": 1000,
"add_individual_results": true,
"plot": "https://rest-dev.texta.ee/data/media/38a0acdeec9565d02c01204a67e89e.png",
"task": {
"id": 163520,
"status": "completed",
"progress": 100.0,
"step": "",
"errors": "[]",
"time_started": "2021-07-20T17:10:42.583184+03:00",
"last_update": null,
"time_completed": "2021-07-20T17:10:43.129320+03:00",
"total": 0,
"num_processed": 0
}
}
Usage¶
Individual Results¶
While the main view of the Evaluator displays only the average results of all classes, this function can be used for retrieving individual results for each class.
Märkus
This function is applicable only for evaluating multiclass / multilabel results.
Parameters¶
- min_count:
Retrieve results only for the classes, which true count (the number of true examples for the class) exceeds this value.
- max_count:
Retrieves results only for the classes, which true count (the number of true examples for this class) is smaller than this value.
- metric_restrictions:
Allows setting restrictions for all scores (precision, recall, accuracy, f1) and results are retrieved only for the classes, which satisfy the restrictions.
The required format for this parameter is the following:
{<metric_i>: {"min_score": <min_score>, "max_score": <max_score>}}
For example, the following restrictions are requiring that precision should be between 0.7 and 1.0 and recall between 0.5 and 1.0:
{"precision": {"min_score": 0.7, "max_score": 1.0}, "recall": {"min_score": 0.5, "max_score": 1.0}}
NB! The default restrictions for each metric are: {„min_score“: 0, „max_score“: 1.0}, so it is not necessary to pass both of these keys, if the purpose is only restricting one of them.
- order_by:
How to order the results? Allowed options are:
„alphabetic“
„count“
„precision“
„recall“
„f1_score“
„accuracy“
- order_desc:
Whether the results should be sorted in descending order or not.
GUI¶
Navigate to Actions by clicking on the three vertical dots at the end of the Evaluator instance’s row and select action „Individual results“ by clicking on it (Joonis 32).
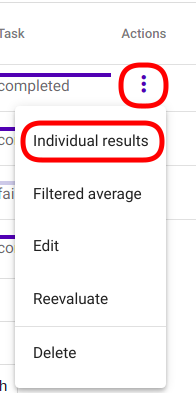
Joonis 32 Select „Individual results“ from Evaluator actions¶
Currently, the GUI does not support passing extra parameters for this function and the results are displayed for all the classes in alphabetical order.
API¶
Endpoint /projects/{project_pk}/evaluators/{evaluator_id}/individual_results/
GET requests retrieves results for each class as an alphabetically ordered dict:
Example:
curl -X GET "http://localhost:8000/api/v1/projects/1/evaluators/148/individual_results/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Response:
{
"arts and culture": {
"precision": 0.875,
"recall": 0.84,
"f1_score": 0.8571428571428572,
"accuracy": 0.9787878787878788,
"confusion_matrix": [[302, 3], [4, 21]]
},
"entertainment": {
"precision": 0.0,
"recall": 0.0,
"f1_score": 0.0,
"accuracy": 0.9757575757575757,
"confusion_matrix": [[322, 0], [8, 0]]
},
"sports": {
"precision": 0.5588235294117647,
"recall": 0.76,
"f1_score": 0.6440677966101696,
"accuracy": 0.9363636363636364,
"confusion_matrix": [[290, 15], [6, 19]]
}
}
POST request allows passing the parameters described above.
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/evaluators/148/individual_results/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"metric_restrictions": {"precision": {"min_score": 0.5}},
"order_by": "f1_score",
"order_desc": false
}'
Response:
{
"total": 2,
"filtered_results": {
"sports": {
"precision": 0.5588235294117647,
"recall": 0.76,
"f1_score": 0.6440677966101696,
"accuracy": 0.9363636363636364,
"confusion_matrix": [[290, 15], [6, 19]],
"count": 40
},
"arts and culture": {
"precision": 0.875,
"recall": 0.84,
"f1_score": 0.8571428571428572,
"accuracy": 0.9787878787878788,
"confusion_matrix": [[302, 3], [4, 21]],
"count": 28
}
}
}
Filtered Average¶
This function allows filtering the final (average) result by setting various restrictions. The classes that do not meet the requirements are not included while calculating the final result. This might be useful for excluding outliers that have a strong effect on the average result (classes that have extremely low scores due to very low number of examples etc).
Märkus
This function is applicable only for evaluating multiclass / multilabel results.
Parameters¶
- min_count:
Retrieve results only for the classes, which true count (the number of true examples for the class) exceeds this value.
- max_count:
Retrieves results only for the classes, which true count (the number of true examples for this class) is smaller than this value.
- metric_restrictions:
Allows setting restrictions for all scores (precision, recall, accuracy, f1) and results are retrieved only for the classes, which satisfy the restrictions.
The required format for this parameter is the following:
{<metric_i>: {"min_score": <min_score>, "max_score": <max_score>}}
For example, the following restrictions are requiring that precision should be between 0.7 and 1.0 and recall between 0.5 and 1.0:
{"precision": {"min_score": 0.7, "max_score": 1.0}, "recall": {"min_score": 0.5, "max_score": 1.0}}
NB! The default restrictions for each metric are: {„min_score“: 0, „max_score“: 1.0}, so it is not necessary to pass both of these keys, if the purpose is only restricting one of them.
GUI¶
Navigate to Actions by clicking on the three vertical dots at the end of the Evaluator instance’s row and elect action „Filtered average by clicking on it (Joonis 33).
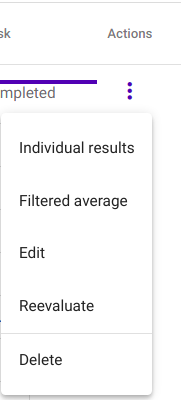
Joonis 33 Select „Filtered average“ from Evaluator actions¶
After clicking on the button, a new window with label „Filtered average“ opens and you can apply different restrictions in there by modifying the applicable parameters. After pushing the button „Apply restrictions“ in the bottom right corner of the window, the average scores are re-calculated in the same window based on the set restrictions (Joonis 34)
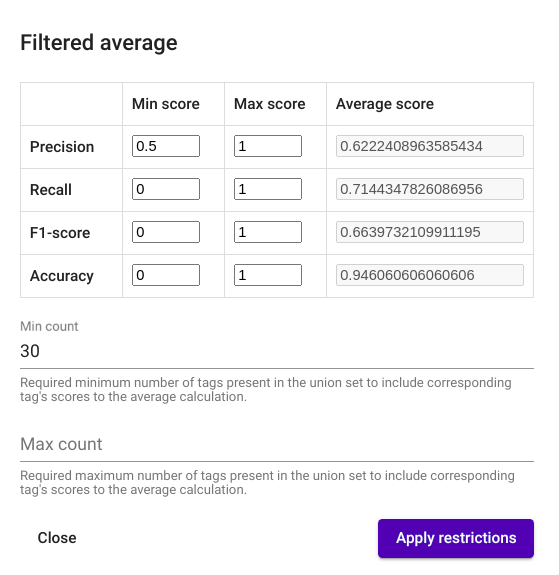
Joonis 34 „Filtered average“ window¶
API¶
Endpoint /projects/{project_pk}/evaluators/{evaluator_id}/filtered_average/
GET requests retrieves the average result based on all the classes.
Example:
curl -X GET "http://localhost:8000/api/v1/projects/1/evaluators/148/filtered_average/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049"
Response:
{
"precision": 0.5965930690458002,
"recall": 0.6007505175983435,
"f1_score": 0.5940300165488676,
"accuracy": 0.9471861471861471,
"count": 14
}
POST request allows passing the parameters described above.
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/evaluators/148/filtered_average/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"metric_restrictions": {"precision": {"min_score": 0.5}},
"min_count": 30
}'
Response:
{
"precision": 0.6222408963585434,
"recall": 0.7144347826086956,
"f1_score": 0.6639732109911195,
"accuracy": 0.946060606060606,
"count": 5
}