Search Query Tagger¶
Search Query Tagger is a tool for tagging documents based on predefined Elasticsearch queries.
Note
Search Query Tagger is applicable only for tagging documents indexed in Elasticsearch and can only be used on indices that contain the same fields as the defined search.
Creation¶
Parameters¶
- description:
Name of the Search Query Tagger task. This is necessary only for differentiating between all the Search Query Tagger tasks in the project.
- indices:
List of Elasticsearch indices containing the documents we wish to tag. NB! Indices should be formatted as list of dicts, where key = “name” and value = <index_name>, e.g:
[{"name": "my_dataset"}]
- fields:
List of field names (as strings) to be added as “doc_path” in the generated Texta Facts. The only requirement is that at least one selected field should be present in each selected index. For example, if we have two indices A and B, where A consists of fields [“text”, “id”] and B of fields [“body”, “doc_id”] and the search requires that the word “cat” must be present in either in the field “text” or “body”, then the possible combinations for fields in Search Query Tagger are: [“body”, “text”], [“body”, “id”], [“text”, “doc_id”], [“id”, “doc_id”] as one field for each index should be present. If we have selected multiple indices and they all contain a field with the same name (e.g. “text”), it is sufficient to only add this field.
- query:
The query restricting the set of documents we wish to tag. In the API, the query should be formatted as a JSON string.
- fact_name:
A general label of the tag (e.g. “TOPIC”) to be added as “fact” in Texta Facts.
- fact_value:
A more specific label of the tag (e.g. “baseball”) to be added as “str_val” in Texta Facts.
- scroll_size (GUI) / bulk_size (API):
Indicates how many documents are processed per one scroll.
- es_timeout:
After how many minutes of processing one batch of documents (n documents in batch = scroll_size) Elasticsearch throws a timeout and the processing is suspended.
GUI¶
To use the Search Query Tagger, we should first define a search (aka query) restricting the documents we wish to tag (navigate to “Search””). In the following example, we have restricted the search to documents containing either the word “usa” or “america” and saved it with title “USA” (Fig. 137).
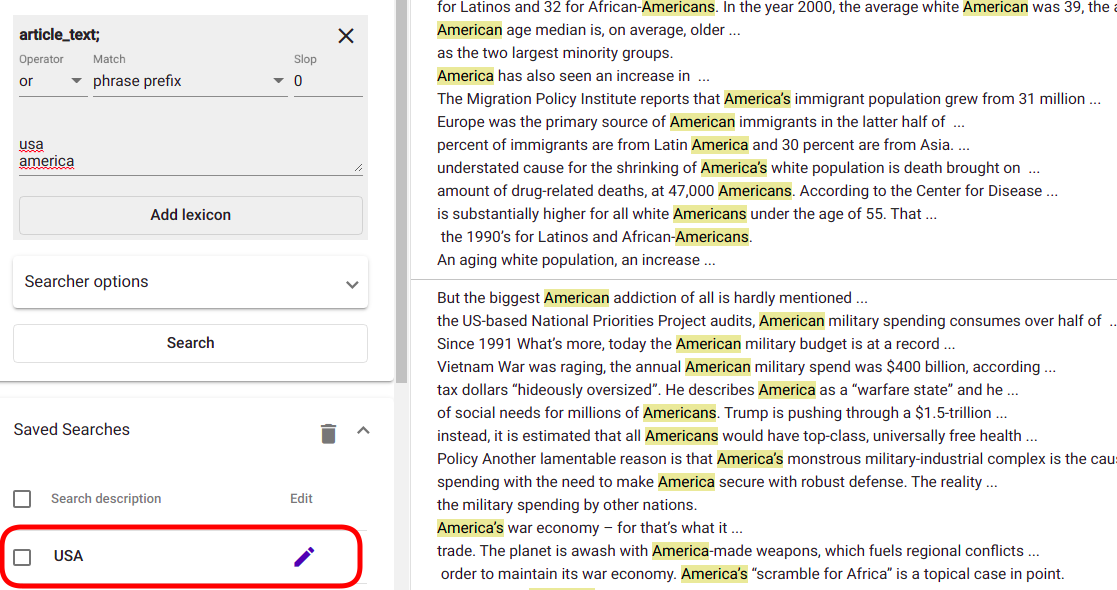
Fig. 137 Defining the search¶
Now we can navigate to Search Query Tagger (“Models” -> “Search Query Taggers”) and use the defined search for tagging all the relevant documents. For creating a new Search Query Tagger task, click on the button “CREATE” in the upper left corner of the page. A new window with the title “New Search Query Tagger Task” opens as a result. Fill all the required fields and select the search you wish to use for tagging the documents (Fig. 138). Then click on the button “Create” in the bottom right corner of the window. The new Search Query Tagger task should now appear as a new row in the list of Search Query Tagger tasks on the same page (if not, try refreshing the page).
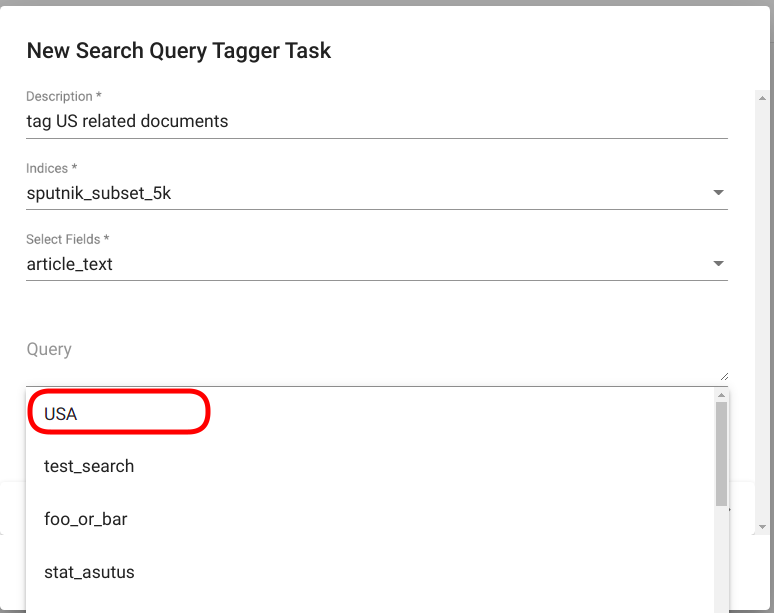
Fig. 138 Select a predefined search¶
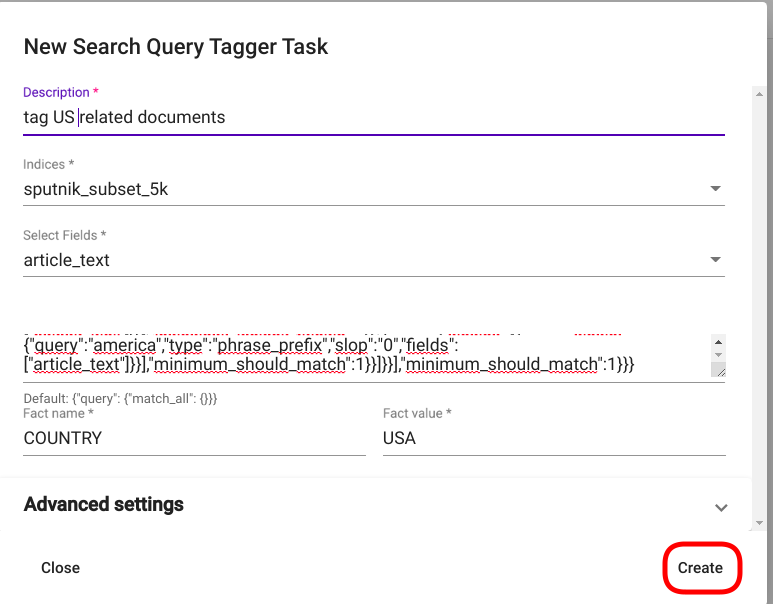
Fig. 139 Search Query Tagger creation window¶
After the task has finished (status = “completed”), you can view the results in Search by either using the same query you used for restricting the search or by searching the newly created fact from field “texta_facts[fact_value]”. Either way, there should be a new fact in field “texta_facts” for every document in the restricted search (Fig. 140).
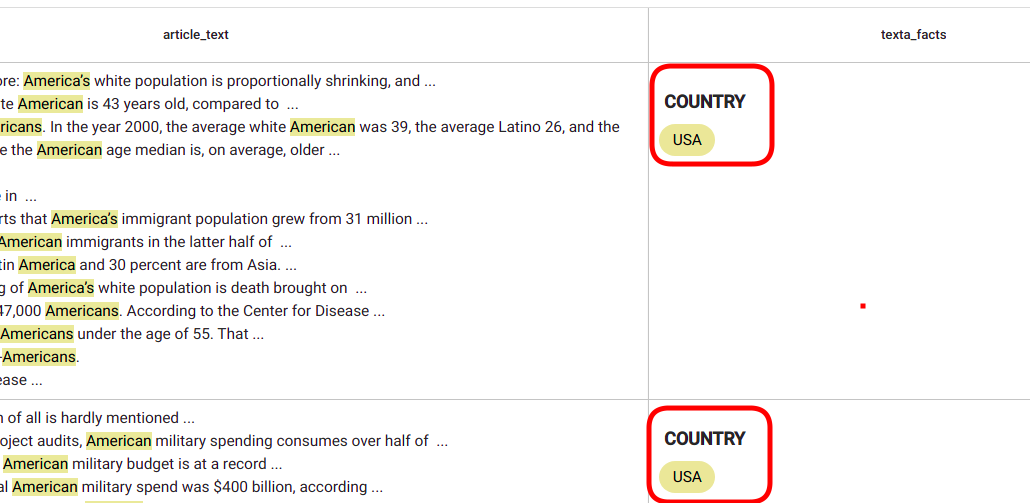
Fig. 140 New fact is added to every document corresponding to the predefined query¶
You can also make sure if all the necessary documents were tagged by comparing the number of documents restricted by the search (search should in this case be restricted with the original query - “USA” in our example) (Fig. 141) with the number of relevant facts returned by an aggregation on field “texta_facts” (Fig. 142 and Fig. 143).

Fig. 141 Number of documents corresponding to the query¶
Fig. 142 Aggregation on field “texta_facts”¶

Fig. 143 Number of relevant facts corresponding to the aggregation¶
API¶
Endpoint /projects/{project_pk}/search_query_tagger/
Example:
curl -X POST "http://localhost:8000/api/v1/projects/1/search_query_tagger/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: Token 8229898dccf960714a9fa22662b214005aa2b049" \
-d '{
"indices": [{"name": "sputnik_subset_5k"}],
"description": "tag US related documents",
"query": "{\"query\":{\"bool\":{\"must\":[],\"filter\":[],\"must_not\":[],\"should\":[{\"bool\":{\"should\":[{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"usa\",\"type\":\"phrase_prefix\",\"slop\":\"0\",\"fields\":[\"article_text\"]}}],\"minimum_should_match\":1}},{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"america\",\"type\":\"phrase_prefix\",\"slop\":\"0\",\"fields\":[\"article_text\"]}}],\"minimum_should_match\":1}}]}}],\"minimum_should_match\":1}}}",
"fields": ["article_text"],
"fact_name": "COUNRTY",
"fact_value": "USA"
}'
Response:
{
"id": 10,
"url": "https://rest-dev.texta.ee/api/v2/projects/291/elastic/search_query_tagger/10/",
"author_username": "test_user",
"indices": [
{
"id": 3938,
"is_open": true,
"url": "https://rest-dev.texta.ee/api/v2/elastic/index/3938/",
"name": "sputnik_subset_5k",
"description": "Subset of sputnik for some demo examples",
"added_by": "test_user",
"test": true,
"source": "Spuntik",
"client": "",
"domain": "news articles",
"created_at": "2021-07-21T11:05:01.072000+03:00"
}
],
"description": "tag US related documents",
"task": {
"id": 163524,
"status": "completed",
"progress": 100.0,
"step": "",
"errors": "[]",
"time_started": "2021-07-21T14:10:43.619657+03:00",
"last_update": "2021-07-21T14:10:47.988791+03:00",
"time_completed": "2021-07-21T14:10:50.068035+03:00",
"total": 0,
"num_processed": 0
},
"query": "{\"query\":{\"bool\":{\"must\":[],\"filter\":[],\"must_not\":[],\"should\":[{\"bool\":{\"should\":[{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"usa\",\"type\":\"phrase_prefix\",\"slop\":\"0\",\"fields\":[\"article_text\"]}}],\"minimum_should_match\":1}},{\"bool\":{\"should\":[{\"multi_match\":{\"query\":\"america\",\"type\":\"phrase_prefix\",\"slop\":\"0\",\"fields\":[\"article_text\"]}}],\"minimum_should_match\":1}}]}}],\"minimum_should_match\":1}}}",
"fields": [
"article_text"
],
"fact_name": "COUNTRY",
"fact_value": "USA",
"bulk_size": 100,
"es_timeout": 10
}