Tutorial: GUI¶
See dokumentatsioon on TEXTA Toolkiti teise versiooni GUI kohta, mille taustaprogrammiks on Texta Toolkiti RESTful API.
Toolkiti seisund (health of Toolkit)¶
Projects all (Toolkiti avalehel) näeme tehnilist infot TEXTA Toolkiti serveri seisundi kohta. Seal on mitmeid mõõdikuid, mis kirjeldavad Toolkiti ja masina, milles see töötab, seisundit (Joonis 4):
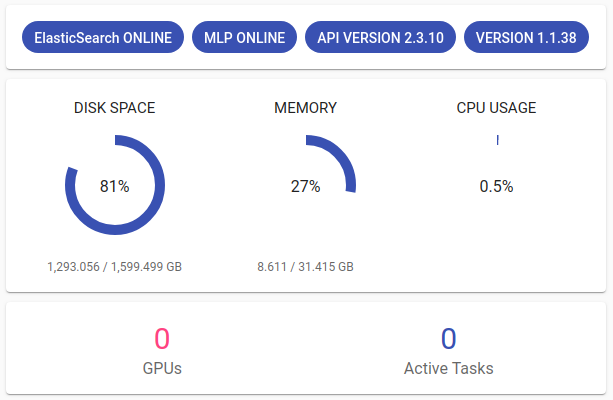
Joonis 4. Toolkiti staatus¶
Registreerimine ja sisse logimine¶
Kuna TEXTA Toolkit on veebirakendus, peame navigeerima vastavale aadressile oma brauseris (nt http://localhost/). Joonisel 1 on näha sisselogimislehte.
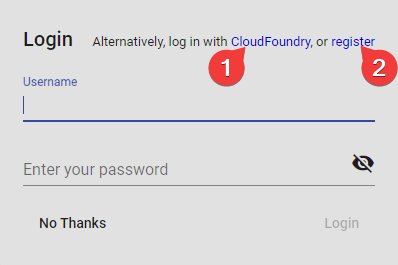
Joonis 1. Sisselogimisleht¶
Registreerimislehel saab registreerida uusi kasutajaid:
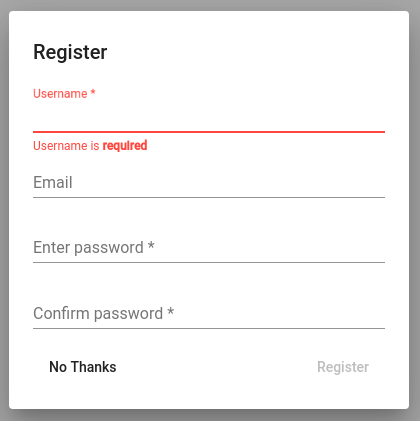
Joonis 2. Registreerimisleht¶
Märkus
Toolkiti esimest korda jooksutamisel uuri vaikimisi installimise ajal loodud superkasutaja kontot admin.
Peale sisse logimist on ülemisel ribal ehk ülapaneelil mitu valikut. Seal võib näha oma projekte (see vaade on ka avalehena) ja oma projektidega töötada erinevate tööriistadega: Search, Lexicons, Models ja Tools.

Joonis 3. Ülapaneel navigeerimiseks¶
Projects¶
Projekti loomine¶
Andmestikuga mängimiseks on vaja luua uus projekt. Uut projekti saab luua vajutades + CREATE nupule lehe allosas. Seejärel saab projektile anda nime, valida projektiga tegelevad kasutajad ning, muidugi, kõige tähtsama - andmestiku, millel mängima hakata (Elasticsearchi indeksites).
Pärast projekti loomist on uut projekti näha projektide nimekirjas. Edit nupuga saab jooksvalt muuta projekti andmestikke ja kasutajate ligipääse.
Projekti kasutamine¶
Projektis töötamiseks (valitud andmestikul info otsimiseks ja märgendajate (Taggers) treenimiseks) peame valima projektinime ülemisel ribal kasutajanime kõrval:

Joonis 5. Projekti valimine¶
Märkus
Korraga saab aktiveeritud olla ainult üks projekt.
Igal projektil võib olla üks või rohkem andmestikku (Elasticsearchi indeksit).
Kasutajad, kellel on ligipääs antud projektile, jagavad projekti ressursse.
Search¶
Otsingurakenduses (Search) saab andmeid lehitseda ja kokku võtta ning luua andmete alamhulki, mida saab hiljem kasutada Toolkiti järgmistes rakendustes.
Märkus
Search-i kasutamiseks peab olema projekt aktiveeritud (valitud) ülapaneelil.
Otsingu graafilises kasutajaliideses on mitu olulist paneeli (kujutatud Joonisel 6). Me saame neid avada või kokku panna, kui vajutame paneeli nurgas olevale noolekesele.
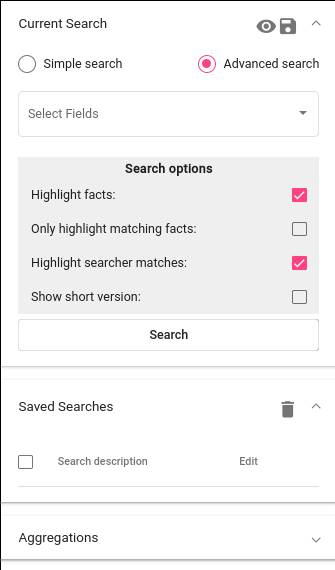
Current Search¶
Andmete lehitsemine ja kokkuvõtete tegemine sõltub otsingutest. Otsing on hulk piiranguid mingi(te)le välja väärtustele. Andmete filtreerimiseks saab defineerida oma piirangud*Current Search* paneelil. Seni, kuni ei salvestata oma piiranguid, ollakse “testimisrežiimis”, mis tähendab, et otsingut saab kasutada ja uurida Search-is, aga ei saa seda kasutada teistes vahendites. Salvestamine muudab selle teistele vahenditele kättesaadavaks.
Otsingule piirangute lisamiseks tuleb valida üks või enam välja (field). Kui väli on valitud, saab täpsustada, millised tekstiühikud (sõnad või sõnaosad) peavad või võiksid esineda huvipakkuvate dokumentide alamhulgas.
Piirangutega otsing tehakse sellel Projekti andmestikul, mis on valitud ülapaneelil.
Oletame, et me soovime leida üles dokumendid, mis sisaldavad sõnu “bribery” ja “official”. Joonisel 7 on lisatud otsingule piirang, mis väljastab ainult need dokumendid, mis sialdavad sõnu “bribery” ja “official” article_text_mlp.text väljas:
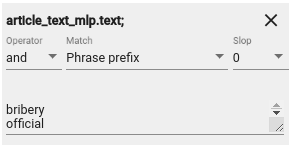
Joonis 7. Näidis otsingu piirangutest¶
Otsingule piiranguid seades võime arvestada erinevate parameetritega:
Operator-i all saab valida ‘or’ või ‘not’. See määrab, kas otsing väljastab dokumendid, mis sisaldavad vähemalt ühte piirangusõnadest (‘or’) või kindlasti mitte ühtegi piirangusõnadest (‘not’).
Piirangu all saame valida ka Match-tüüpi. Tüüp “word” otsib kirjutatud sõna(de) täpsed vasted, “phrase” otsib kirjutatud fraaside täpsed vasted. “Phrase prefix” leiab kattuvate prefiksitega (sõnade alguste) sõnadega dokumendid. See tähendab, et sõnade tegelikud lõpud võivad erineda: nt otsides sõna ‘bribe’, leitakse üles ka sõnad ‘bribetaking’, ‘bribers’, ‘bribery’ jms, mille algus on ‘bribe’. ‚regex‘-i abil saab kasutada regulaaravaldisi. Seda valides võetaksegi piirangut regluaaravaldisena. Näiteks piirang ‚bribe.{0,2}‘ leiab üles sõnad ‚bribe‘ ja ‚bribery‘, aga mitte pikemaid sõnu. Kui piirangsõnade nimekiri osutub pikaks, on võimalik pikendada väljaotsingu paneeli.
Piiranguparameetrite arsenalis on ka Slop. Slop-iga saab määrata, mitu sõna võib olla kahe samale reale kirjutatud sõna vahel (juhul, kui antud vahemik on meile tähtis).
Otsingut saab muuta detailsemaks, lisades juurde eelmistega sarnaseid piiranguid Add Filter nupu abil. Näiteks on võimalik otsida dokumente teatud ajavahemikust juhul, kui meil on korralikult eeltöödeldud kuupäevaväli.
“Search” nupule klõpsates näeme piirangutele vastavaid andmeid tabelina (vt Joonist 8), kus piirangute vasted on roosaga esile tõstetud. Tulemused võivad end värskendada otsingupiirangute muutmise ajal.
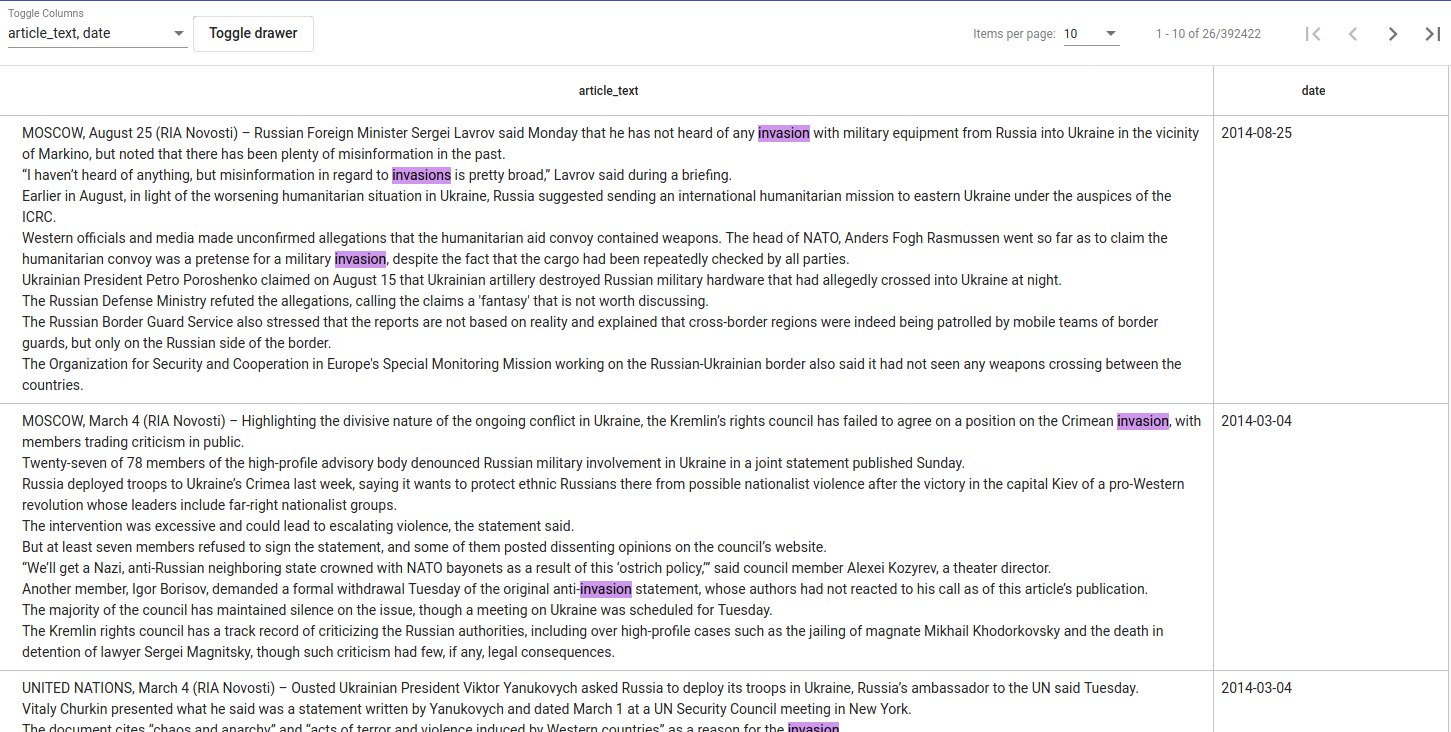
Joonus 8. Otsingu tulemuste näidis¶
Kui tunnuseid (tulpi) on liiga palju, saab neid varjata rippmenüüst all vasakult. Seal on võimalik neid valida või valikust maha võtta korraga (Select all) või neile eraldi klõpsates. Samuti saab Toggle drawer nupuga peita või tagasi võtta Otsingu paneele. Otsingu tulemusi saab lehitseda all paremal oleva noolekese abil. Samuti on võimalik valida, mitut dokumenti ühel lehel soovitakse näha.

Joonis 9. Otsingu tulemuste väljade valimine¶
Sobiva otsingu saab salvestada pärastiseks diski ikooni abiga Current Searchi paneeli ülal paremal. Silma ikoon diski ikooni kõrval näitab tegelikku Elasticsearch query-t, mida antud otsingupiirangute loomisel ehitati.
Salvestatud otsingud¶
Otsingu salvestamine lubab saadud dokumentide alamhulka kasutada teistes Toolkiti vahendites. Otsingut valides saab andmeid hiljem uuesti lehitseda või neid kasutada agregatsioonides. Salvestatud otsinguid saab saata ka teistele kasutajatele, kellel on ligipääsuluba antud projektile, otsingu url-iga. See url avab salvestatud otsingu Current Search-i all teisele kasutajale. Salvestatud otsingule klõpsamine avab selle Current Search-i all.
Agregatsioonid: Andmete kiiranalüüs¶
Kuigi andmete taoline lehitsemine on väga vahva, ei pruugi see alati piisav olla. Mõnikord on vaja andmetest saada kiirem ülevaade näiteks teemade muutustest ajas või sõnade jaotustest. Searcheri all saab teha kõike seda ja enamgi veel “Aggregations” (Agregatsioonide) paneeli all.
Agregatsioonidel on kaks komponenti - andmed ja tunnused, üle mille see agregeerib. See agregeerib üle andmete, mis on Current Searchi all. Current Search-i saab ka välistada (‚Agregeeri üle kogu andmestiku, välja arvatud selle osa, mis on hetkel aktiivne‘) ja valida agregatsiooni suurust. Tulemusi saame grupeerida valitud tunnuse (feature) kaupa ning näha kategooriate sagedust. Oletame, et meid huvitab, millised on sagedaseimad sõnad meie leitud “bribe” sõnaalgustega dokumentide alamhulgas. Selleks vajutame oma bribe otsingule Saved Searches-i all, et saada see Current Searchi alla.
Märkus
- Kuidas on significance-skoorid arvutatud?
Numbrid, mida väljastatakse skooridena, on mõeldud erinevate soovituste mõistlikuks järjestamiseks. Seda ei ole tavakasutajal lihtne mõista. Skoorid saadakse vaadates sõnasagedusi alamhulgas ja koguhulgas. Termineid peetakse märkimisväärseks ehk eristuvaks, kui alamhulga ja kõigi dokumentide vahel on märgata olulist termini sageduse erinevust. Terminite järjestamistingimusi saab muuta, vt „Parameters“ osa.
Veel üks lahe asi, mida Agregatsioonid teha saavad, on kindlate märksõnadega tekstide sageduse kuvamine ajajoonel. Seda saab teha, kui andmetel on olemas korralik kuupäevaväli (Texta date formaadis). Me saame näiteks uurida, millal kasutati sõnu ‚bribe‘, ‚bribery‘ ja ‚bribed‘ kõige rohkem meie andmestikus.
Üle texta_facts välja agregeerimine väljastab mingi märgendi (täägi) all olevad sagedaseimad olemid. Musta diagrammi nupu alt leiab tulemused. Agregatsiooni suuruse alt saab valida, mitut olemit näha soovitakse.
MLP¶
Andmete eeltõõtlemine on masinõppes standardprotseduur mida TTK-s võimaldab teha MLP (multilingual preprocessor) moodul.
Selle kasutamiseks liigu menüüs Tools -> MLP. Vajuta Create nuppu et luua uus MLP lõim. Vali indeksid ja väljal, millele soovid MLP-d rakendada. Kuna MLP rakendamine andmetele võib võrdlemisi palju aega võtta, on rangelt soovituslik valida ainult väljad, millele MLP rakendamiseks on ka päriselt kasu. See tähendab, et valima peaks ainult väljad, mida on plaanis hiljem kasutada leksikonide loomiseks või mudelite treenimiseks. Viimaks vali analüsaatorid, mida soovid andmetel rakendada.
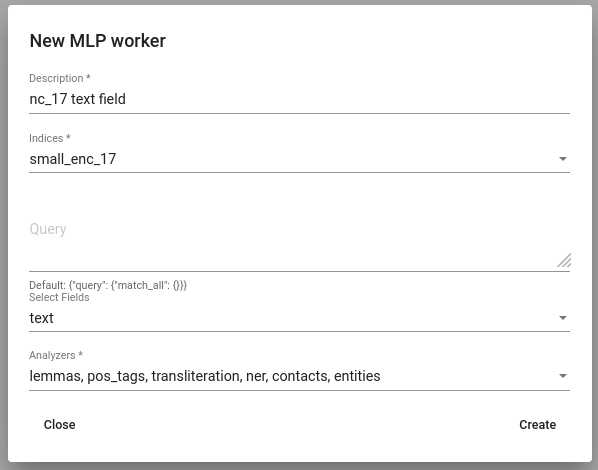
Joonis 10. MLP lõime loomine¶
MLP rakendamise tulemusena lisatakse andmestikule uued välja, mis sisaldavad analüsaatorite tulemusi. Neid saab näha näiteks Search-is.
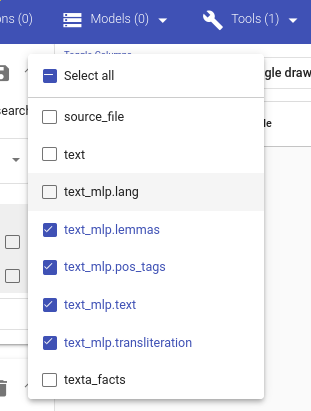
Figure 11. Ued, MLP tulemusi sisaldavad väljad.¶
Lexicon Miner¶
Leksikonide loomiseks peab olemas olema varem treenitud Embeddingu mudel. Alles siis saab alustada teema leksikonide loomist.
Loome leksikoni, mis sisaldab sõnaga “bribery” kaasas olevaid verbe.
Pärast vastloodud leksikoni peale vajutamist on tarvis lisada mõned seemnesõnad nagu ‚accuse‘.
Leksikoni loomine (või täiendamine) on iteratiivne protsess. Uusi soovitusi saab pidevalt juurde küsida ning nende seast tuleb valida need, mis tunduvad loogilised. Uusi soovitusi tasub juurde küsida, kuni ükski neist ei ole enam tähenduslikult sobiv. Valimata jäänud sõnad ilmuvad leksikoni alla negatiivsete näidetena. Neid võetakse otsitavate tähenduste vastandtähendustena. Sõnu saab negatiivsete sõnade listist kustutada nende peale klõpsates.
Sobiva sõna leksikoni lisamiseks tuleb sellele klõpsata. Leksikoni valitud sõnad ei jää sinna kinni, juba valitud sõnu on võimalik leksikonist kustutada.
Kui leksikon on valmis, saab selle salvestada.
Embeddings¶
Ülapaneelil oleva Models-i all saame kasutada erinevaid märgendajaid ja luua sõnavektoreid.
Sõnavektorid on põhimõtteliselt arvutile arusaadavamasse numbrilisse vormi (vektoritsesse) teisendatud sõnad, mis on masina jaoks loogilisemad, kui tühipaljad sõned (sõnad). Loodud vektorite abil on võimalik sõnu võrrelda või leida sarnaseid. Sõnavektoreid on vaja näiteks leksikonide tarbeks. Texta Toolkit kasutab word2vec sõnavektoreid collocation detection-iga. Viimane tähendab, vektoreid luuakse nii sõnadele kui ka fraasidele. Fraasid valib välja collocation detection (kollokatsioonide tuvasti), mis tuvastab tihti koos esinevaid sõnu ja märgib need fraasideks.
All vasakul oleva ‚+ CREATE‘ nupuga saame alustada uut sõnavektorite treeningut. Esiteks tuleb valida uuele keelemudelile (sõnavektorite hulgale) nimi (Description). Query osa tühjaks jätmine tähendab seda, et treeningusse läheb kogu aktiivse projekti andmestik. Soovituks sisendiks saab valida ka salvestatud leksikone. Seejärel tuleb valida väljad, millel sõnavektorid treenitakse. Sõnavektorid vajavad tekstilist sisendit, seetõttu tuleb valida väljad teksti või lemmatiseeritud tekstiga. Ühest väljast piisab. Üldjuhul eelistatakse lemmatiseeritud tekse. Seda eriti morfoloogiliselt rikaste keelte puhul, kuna see suurendab mõne sõna sagedust (söönud, sööb ja sõid saavad oma lemmaks sööma).
Seejärel tuleb valida dimensioonide arv. Dimensioonide arv tähendab loodavate vektorite pikkust. 100-200 dimensiooni on tavaliselt hea valik, millest alustada. Miinimumsagedus (minimum frequency) määrab, mitu korda peab sõna või fraas andmestikus esinema, et saada endale oma sõnavektor. Haruldased sõnad/fraasid ei saa endale väga informatiivseid ja kasutatavaid vektoreid. Kui Sa pole väga kindel, mida valida, on alustuseks vaikimisi määratud 5 sobiv.
Pea meeles - mida suurem on andmestik, seda paremad on tulemused!
Sõnavektorite treenimistabelist saab vaadata infot sõnavektorite treenimisprotsesside ja tulemuste kohta. Näiteks saab sealt vaadata, milline kasutaja treenis antud sõnavektorid selles projektis; mis on sõnavektorite mudeli nimi; millis(t)el välja(de)l need treenitud on; kui kaua võttis treenimine aega; millised on dimensioonid, miinimumsagedused ja loodud sõnavara suurus. Uue mudeli reale klõpsates ilmub sarnane info uuesti nähtavale.
Kolm punktikest Edit-i all avab sõnavektori mudeli kustutamise võimaluse või lubab kasutada Phrase-i. Phrase on abivahend, mis võimaldab kontrollida, millised fraasid on selles mudelis saanud endale oma sõnavektorid. See väljastab sõnad ja ühendab fraasid ‚_‘-märgiga. Proovime treenida sõnavektorite mudelit oma salvestatud ‚bribery‘ otsingu peal (joonis 10). Kui me jätaksime query-osa tühjaks, treenitaks mudel kogu andmestiku peal.
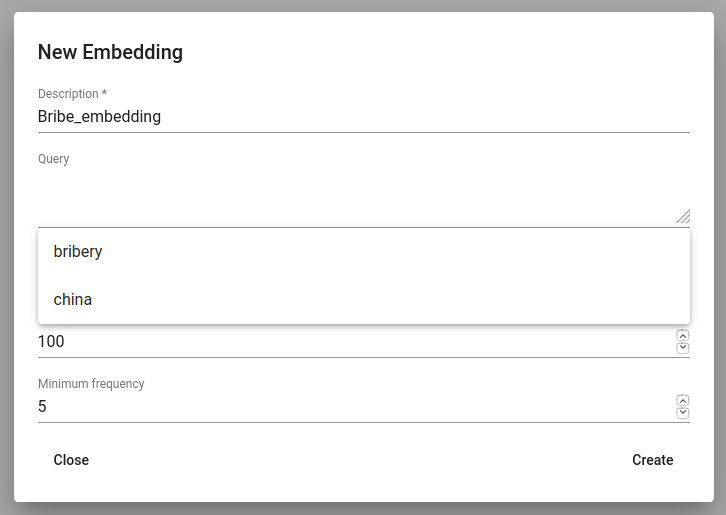
Joonis 12. Salvestatud otsinguga sõnavektorite mudeli loomine¶
Taggers¶
Erinevad märgendajad (Taggers) Texta Toolkitis on klassifitseerimismudelid, mis annavad uuele andmestikule vastava sildi/klassi, mille suhtes mudel treenitud on. Märgendajat saab saab kasutada ka üle API.
Toolkitis on kaks märgendajat:
Vaid Tagger-it saab treenida ka salvestatud otsingute peal (otsing kui ühe klassi kogum). Teised treenivad oma mudeleid kogu andmestiku märgendite peal. Järgnev on juhis nende märgendajate treenimiseks.
Märgendaja (Taggers) treenimine
Tagger märgendaja töötab salvestatud otsingutega ning kasutab masinõpet. Uut Tagger mudelit saab luua vajutades all vasakul olevat ‚+CREATE‘ nuppu. Seejärel tuleb välja mõelda märgendaja nimi (Description) ja mudeli sisendiks saavad väljad. Kui valitakse kaks välja, siis nende väljade sisu lihtsalt kleebitakse kokku enne treenimisprotsessi. Ka ühest väljast piisab. Üldjuhul eelistatakse lemmatiseeritud teksti, eriti morfoloogiliselt rikaste keelte puhul, kuna see tõstab mõnede sõnade esinemissagedust (söödud, sööb ja sõin muutuvad oma lemmaks sööma ja neid saab vaadelda ühe sõnana).
Tühi Query võtab sisendiks kogu andmestiku aktiivses projektis. Soovitud sisendiks võib valida ka salvestatud otsingu. Salvestatud otsing on märgendajale positiivsete näidete kogum - hiljem märgendab mudel sellele otsingukogumile sarnaseid andmeid.
Kui need kolm parameetrit on valitud, saab alustada klassifitseerija treenimist. Soovi korral on võimalik muuta ka lisaparameetreid, näiteks Vectorizer (Hashing Vectorizer, Count Vectorizer, Tfldf Vectorizer - loe nende kohta rohkem siit) ja Classifier (Logistic Regression, LinearSVC). LinearSVC võib anda errorit, kui salvestatud otsingus on liiga vähe andmeid. Võimalik on määrata ka negative multiplier-it, mis muudab negatiivsete näidete suhet treenimisandmestikus. maximum sample size määrab, mitut näidet ühe klassi kohta mudel treenides näeb.
Lõpetuseks tuleb vajutada Create-nuppu. Seejärel on võimalik vaadata märgendaja treenimisprotsessi ja tulemusi.
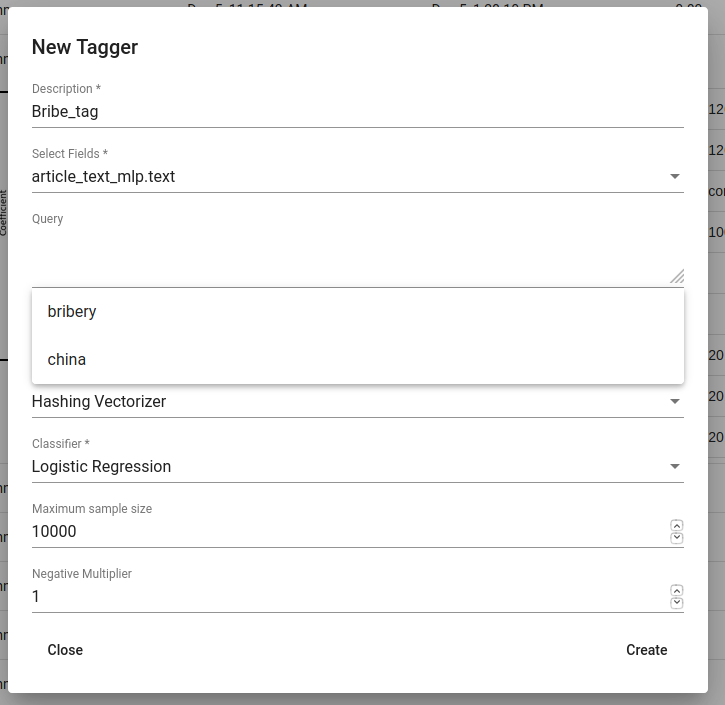
Joonis 13. Bribe_tag märgendaja (Tagger) loomine¶
- Iga uue Tagger mudeli progressi saab jälgida tabelis, mis on Task-i all. Sellele reale vajutamine kuvab kogu treenimisinfo - kui kaua treenimine aega võttis, kui edukas mudel oli. Meeldetuletusena:
Recall ehk saagis on õigesti positiivseks märgendatute ja kõigi positiivsete elementide suhe.
Precision ehk täpsus on õigesti positiivseks märgendatud ja kõigi positiivseks märgendatud elementide suhe.
F1-skoor on nende kahe harmooniline keskmine ning peaks olema informatiivsem, eriti just tasakaalust väljas oleva andmestiku puhul.
Kolm täpikest Edit-i all avab lisategevuste nimekirja.
List features väljastab sõnatunnused ja nende koefitsiendid, mida mudel kasutas. Töötab mudelitega, mis kasutasid Count Vectorizer-it või Tfldf Vectorizer-it, kuna nende väljund on kuvatav.
Retrain tagger treenib kogu märgendaja uuesti samade parameetritega. See on kasulik, kui andmestik muutub või lisatakse uusi stopp-sõnu.
Stop words on stopp-sõnade lisamiseks. Stopp-sõnad on sõnad, mida mudel ei arvesta, kui ta otsib vihjeid sarnasuste kohta. Arukas on lisada nimekirja kõige sagedasemad sõnad nagu olema, mina, sees, kõrvalt. Sõnad tuleb eraldada tühikuga (‚ ‚).
Tag text aitab hõlpsasti kontrollida, kuidas mudel töötab. Sellele vajutades avaneb aken. Aknasse saab kleepida/kirjutada teksti, valida selle lemmatiseerimine (vajalik, kui mudel on treenitud lemmatiseeritud tekstil) ning seejärel see ‚postitada‘ (vajuta Post-nuppu). ‚Postitamine‘ väljastab tulemuse (True, kui antud tekst saab vastava täägi, ja False, kui ei saa) ja ennustuse tõenäosuse (probability). Tõenäosus näitab, kui kindel on antud mudel oma ennustuses.
Tag doc on sarnane Tag text-ile, ainult et sisend on json-formaadis.
Tag random doc võtab suvalise dokumendi andmestikust, väljastab selle ja tagastab tulemuse ja vastavasse klassi kuulumise tõenäosuse.
Delete kustutab mudeli.
Tabeli vaates saame valida mitut mudelit korraga ja kustutada need, kasutades prügikasti nupukest +CREATE nupukese kõrval all vasakul. Mitme mudeli seast saab õiget otsida nende kirjelduse või task status-e kaudu. Kui mudeleid on palju, saame vahetada kuvamislehekülge all paremal.
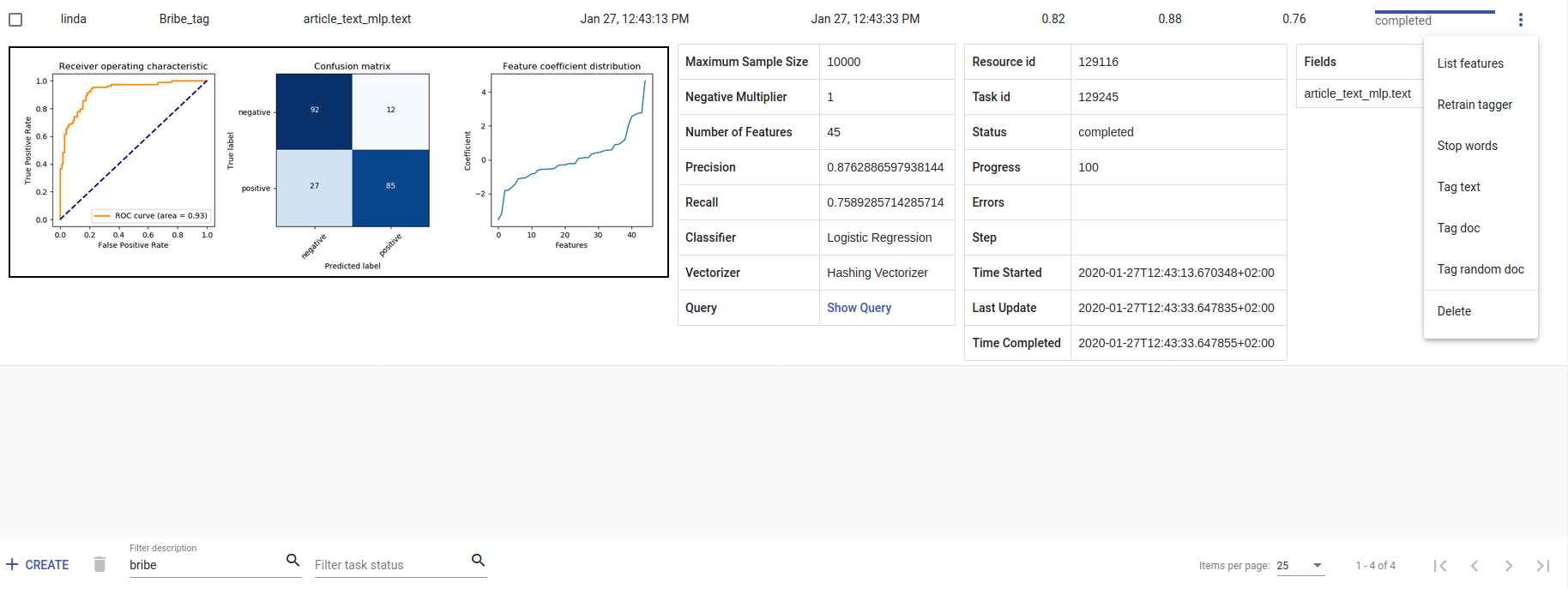
Joonis 14. Bribe_tag märgendaja¶
Tagger Groups-i treenimine
Tagger Group-iga saab treeniga mitme klassi klassifitseerimist korraga ning see kasutab andmestikus olevaid märgendeid.
Märkus
- Kuidas erinevad Tagger ja Tagger Groups?
Üks mudel ennustab, kas tekst on positiivne (True) või negatiivne (False). St, kas tekst saab märgendi või mitte. Tagger treenib vaid ühe mudeli ning ennustab, kas tekst on sarnane sellele andmestikule / salvestatud otsingule, millel see treeniti. Tagger Group treenib mitu mudelit korraga. St, see võib ennustada mitut märgendit korraga. Tagger Group treenib end faktide põhjal. Meil võib olla mitu erinevat väärtust ühe kindla fakti all ning iga väärtuse kohta (kui sellel väärtusel on piisavalt kõrge sagedus (Minimum sample size)) treenitakse eraldi mudel.
Tagger Group mudelit saab luua all vasakul oleva ‚+CREATE‘ nupu abil. Avanenud aknas tuleb valida uuele Tagger Group-ile nimi (Description); faktid, mida mudel õppima hakkab; ja minimaalse sageduse suuruse.
Mudeli sisend on projekti all olev aktiivne andmestik (seda saab kontrollida sinisel ülapaneelil paremal). Andmestikus peab valima väljad, millel mudel õpib. Kui valitakse kaks välja, kleebitakse need lihtsalt kokku enne treenimist. Ka ühest väljast piisab. Üldjuhul eelistatakse lemmatiseeritud teksti, eriti morfoloogiliselt rikaste keeltega, kuna see tõstab mõnede sõnade sagedust (söödud, sööb ja sõi muutuvad oma lemmaks sööma ja neid käsitletakse ühe sõnana).
Olemasolevaid sõnavektoreid saab samuti treenimisse lisada.
Tagger Group-i klassifikaatoreid saab veel sättida lisaparameetritega nagu Vectorizer (võimalikud tunnuste eraldajad on: Hashing Vectorizer, Count Vectorizer, Tfldf Vectorizer - loe rohkem nende kohta siit) ja Classifier (Logistic Regression, LinearSVC). LinearSVC võib anda errorit, kui otsingus ei ole piisavalt andmeid. negative multiplier-i abiga saab muuta negatiivsete näidete osakaalu treenimisandmestikus. maximum sample size määrab, mitut näidet ühe klassi kohta mudel treenides näeb.
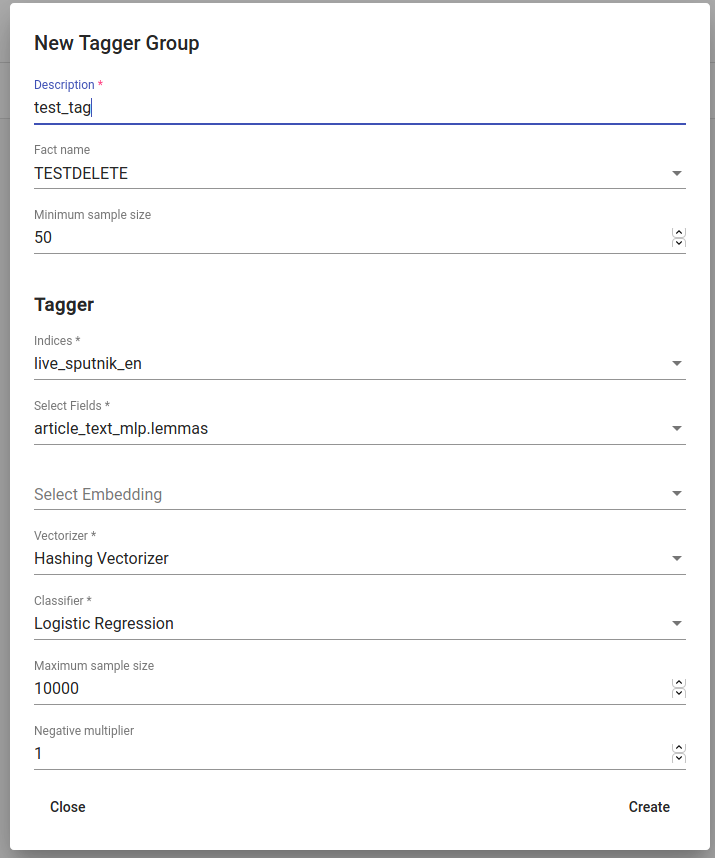
Joonis 15. Tagger Group-i loomine¶
Pärast nende parameetrite sättimist saab vajutada ‚Create‘ ja näha märgendaja tulemusi joonisel 14 näidatud kujul.
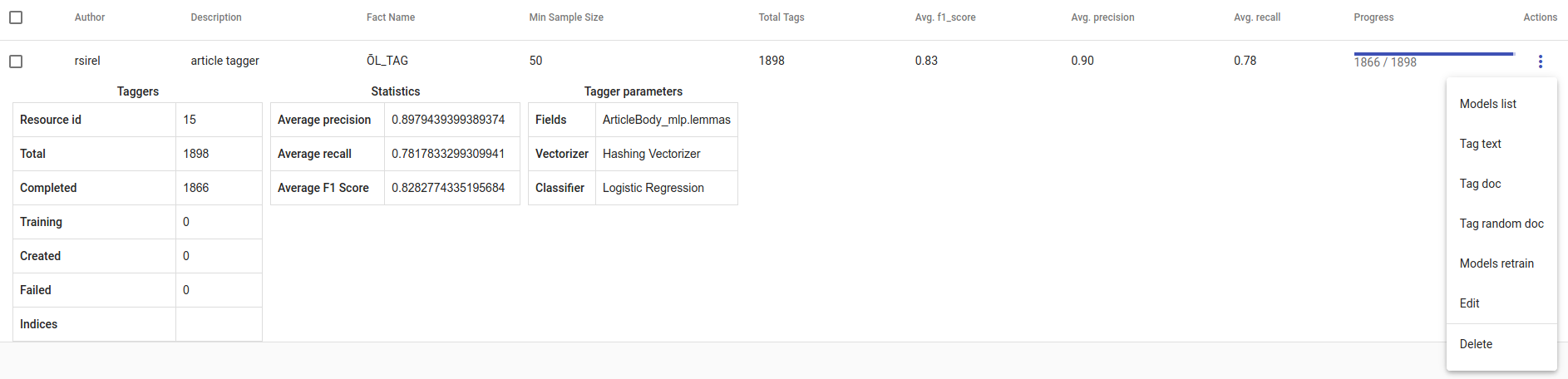
Joonis 16. Loodud Tagger Group¶
- Uue Tagger Group mudeli progressi saab jälgida tabelist, mis ilmub Task-i all. Kui me vajutame mudelile, näeme kogu treenimisinfot - kui kaua treenimine aega võttis ja kui edukas mudel on. Meeldetuletusena:
Recall ehk saagis on õigesti positiivseks märgendatute ja kõigi positiivsete elementide suhe. Avg.recall ehk saagise keskmine on kõigi mudeli saagiste keskmine.
Precision ehk täpsus on õigesti positiivseks märgendatud ja kõigi positiivseks märgendatud elementide suhe. Avg.precision ehk täpsuse keskmine on kõigi mudeli täpsuste keskmine.
F1-skoor on nende kahe harmooniline keskmine ning peaks olema informatiivsem, eriti just tasakaalust väljas oleva andmestiku puhul. Avg.F1_score on kõigi mudeli F1-skooride keskmine.
Kolm täpikest Edit-i all avab lisategevuste nimekirja.
Models retrain treenib kogu Tagger Group-i uuesti samade parameetritega. See on kasulik, kui andmestik muutub või lisatakse uusi stopp-sõnu.
Models list kuvab mudeleid, mille Tagger Group treenis. Sealt saab vaadata, milliseid sildid/märgendid treeniti.
Tag text aitab hõlpsasti kontrollida, kuidas mudel töötab. Sellele vajutades avaneb aken. Aknasse saab kleepida/kirjutada teksti, valida selle lemmatiseerimine (vajalik, kui mudel on treenitud lemmatiseeritud tekstil) ning seejärel see ‚postitada‘ (vajuta Post-nuppu). ‚Postitamine‘ väljastab tulemuse (kõik märgendid, mille kohta mudel ennustas sellele tekstile True) ja iga täägi kohta tõenäosuse (probability), et see märgend käib selle teksti kohta. Tõenäosus näitab, kui kindel on antud mudel oma ennustuses. Number of similar documents on antud dokumendiga sarnaste dokumentide arv. Nendele dokumentidele märgendatud märgendeid testitakse uue antud dokumendi peal.
Tag doc on sarnane Tag text-ile, ainult et sisend on json-formaadis. Number of similar documents on antud dokumendiga sarnaste dokumentide arv. Nendele dokumentidele märgendatud märgendeid testitakse uue antud dokumendi peal.
Tag random doc võtab suvalise dokumendi andmestikust, väljastab selle ja tagastab tulemused ja vastavatesse klassidesse kuulumise tõenäosuse.
Delete kustutab mudeli.
Tabeli vaates saame valida mitu mudelit korraga ja kustutada need, kasutades prügikasti nupukest +CREATE nupukese kõrval all vasakul. Mitme Tagger Groups mudeli seast saab õiget otsida nende kirjelduse või task status-e kaudu. Kui mudeleid on palju, saame vahetada kuvamislehekülge all paremal.
Topic Analyzer¶
Topic Analyzer ehk Teemaanalüsaator on vahend, millega saab andmestikust leida sarnaste dokumentide gruppe ja muuta need grupid ühe sildi alla kuuluvateks klassideks.
Andmestiku grupeerimine
Uue grupeeringu (või klasterdamise, nagu meie seda nimetame) loomiseks navigeeri Models -> Clustering alla ja vajuta „Create“. Sarnaselt Tagger Group-iga peab andma sellele nime (Description), valima indeksid ja väljad, mille põhjal grupeerima hakatakse. Lisaks saab piirata klasterdamises kasutatavat andmestiku Query parameetri kaudu, valides andmestikuks selle alamhulga.
Soovi korral saab teha täppishäälestust, valides klasterdamisalgoritmi ja vectorizer-it ning määrates klastrite arvu (Num clusters) ning dokumendivektori dimensioonide arvu (Num dims).
Märkus
Kuidas valida klastrite arvu?
Üldine nõuanne on, et parem on valida liiga palju klastreid kui liiga vähe. Mõtle, mitut dokumenti hakkad klasterdama, ning vali number nii, et keskmine klaster oleks piisavalt väike, et seda käsitsi hõlpsasti kontrollida. Näiteks, kui klasterdad 1000 dokumenti 50 klastrisse, sisaldab keskmine klaster 20 dokumenti.
document-term matrix-i asemel võib klasterdamisel kasutada ka selle maatriksi tihendatud üldistust (compressed approximation) (parameetriga Use LSI), mis luuakse enne klasterdamist. LSI jaoks on vaja kindlasti määrata teemade arv (dimensioonid ‚low-rank‘ maatriksis) (Num topics all).
Mõnel juhul on juba ette teada, milline antud andmestik, mida klasterdama hakatakse, on. Näiteks võib olla teada, millised on domeeni-spetsiifilised stopp-sõnad, mida võiks ignoreerida. Neid saame lisada väljas Stopwords.
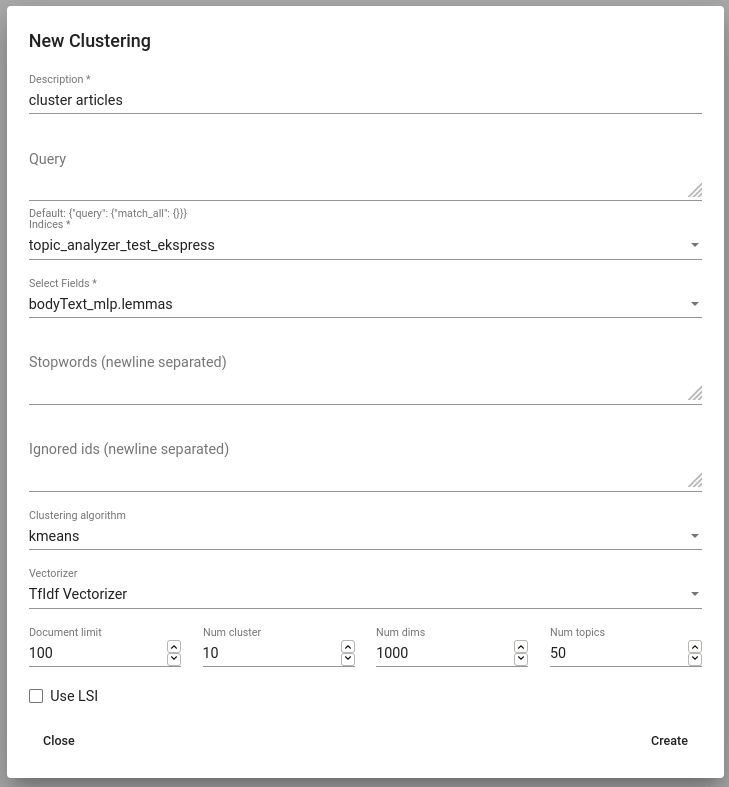
Joonis 17. Klasterdaja loomine¶
Klastrite hindamine
Klastreid saab vaadata Actionite all (View clusters). Sealt saab ülevaate tekitatud klastrite kohta. Iga klastri kohta antakse dokumentide arv ja keskmine koosinussarnasus dokumentide vahel. Lisaks antakse iga klastri oluliste (tähenduslike) sõnade nimekiri - sinna kuuluvad need sõnad, mis võrreldes teiste dokumentidega on märkimisväärselt sagedasemad nendes dokumentides, mis sellesse klastrisse kuuluvad.
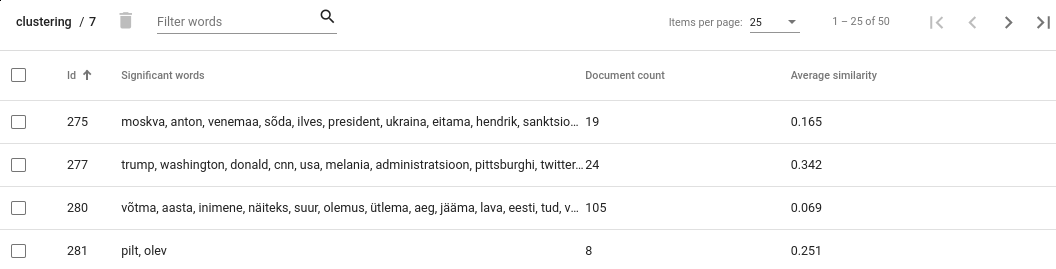
Figure 18. Clusters view¶
Märkus
Dokumendi arvu tõlgendamine
Teiste klastritega märkimisväärselt suurema dokumentide arvuga klaster viitab sellele, et klasterdamisalgoritmil ei õnnestunud nende dokumentide teemadesse jaotamine. See ei pruugi kohe tähendada, et klasterdamisprotsess üleüldiselt ebaõnnestus, kuna tihti ei olegi võimalik kõiki dokumente täiuslikult klasterdada. Siiski tasub sellistele klastritele hoolega otsa vaadata, sest sellist klastrite tekkeks võib olla ka muid põhjuseid. Näiteks võivad dokumendid selles klastris sisaldada sarnast müra või stopp-sõnu, mis teevad neid tehislikult sarnasemaks. Mõnikord võib abiks olla klastrite arvu suurendamine.
Average similarity (keskmise sarnasuse) tõlgendamine
Average similarity on keskmine koosinussarnasus kõigi dokumentide vahel selles klastris. Skoor on vahemikus 0..1 ning mida kõrgem on skoor, seda suurem on sarnasus antud klastri dokumentide vahel. Sellel skooril on ka puuduseid. Näiteks, kui meil on klaster, kus 9 dokumenti on üksteisele väga sarnased ning kümnes dokument väga erinev teistest, võib keskmise koosinussarnasuse skoor näida väga madalana, kuigi selle klastri parandamine oleks väga lihtne.
Klastri sisu nägemiseks tuleb lihtsalt vajutada huvipakkuvale klastrile. See avab detailse klastrivaate Cluster Details.
Klastritega tegelemine
Cluster Details vaade laseb vaadata klastrisse kuuluvaid tegelikke dokumente.
Kui klastri sisu on sobiv, saab selle ära märgendada (täägida) „Tag“ nupu abil. See lisab texta_fact-i kõigile dokumentidele antud klastris koos määratud fakti nime ja väärtusega. Edaspidi ignoreeritakse neid dokumente järgnevates klasterdamise protsessides.
Klastrisisu saab ka käsitsi kohendada, näiteks eemaldada mõned dokumendid. Seda saab teha, valides dokumendid, mis klastrisse ei sobi, ning vajutades prügikastiikoonile. Pane tähele, et neid dokumente ei ignoreerita järgnevates klasterdamise protsessides.
Tõenäoliselt pakub klastrite uurimisel huvi ka see, kas indeksis on veel dokumente, mis on sarnased klastris olevatele. Kui see tõepoolest nii on, võib tekkida soov needki klastrisse lisada, et saaks kõik ühe korraga ära märgendada.
Sarnaste dokumentide leidmiseks on loodud nupp „More like this“. See avab vaate, kus saab valida dokumente, mida soovitakse klastrisse lisada „+“-nupu abil.
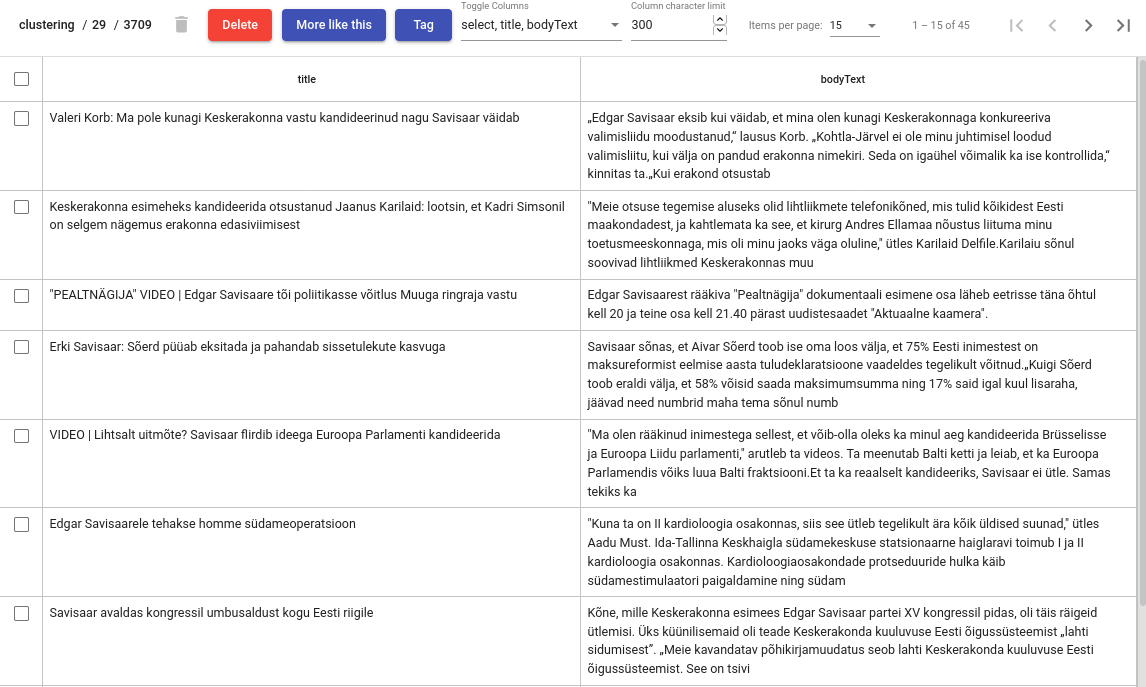
Joonis 19. Klastrite detailne vaade (Cluster details view)¶
Reindexer¶
Reindexer ehk Reindekseerija on kasulik vahend Elasticsearchi indeksite reindekseerimiseks. Indeksist võib mõelda kui oma andmestikust. Reindexeriga saab eemaldada ebasobivad väljad ja muuta väljatüüpi (näiteks saab tekstivälju, mis tegelikult sisaldavad kuupäevi, muuta kuupäevaväljadeks, mida oma agregatsioonides kasutada).
Uut indeksit saab luua ‚+CREATE‘ nupu abil all vasakul.
Description on uue reindekseerimistöö kirjeldus.
New index name on loodava indeksi nimi.
Indices on kõik indeksid, mida tahame oma uude indeksisse.
Field types abil saab muuta välja(de) tüüpi ja/või nime.
Query abil saab lisada uute indeksisse kindlaid otsingutulemusi.
Random subset type abil saab luua indeksi, milles on kindel arv suvaliselt valitud näiteid (ridu). Seda saab kasutada juhul, kui soovitakse testida Toolkiti vahendeid enne nende kogu andmestikule rakendamist.
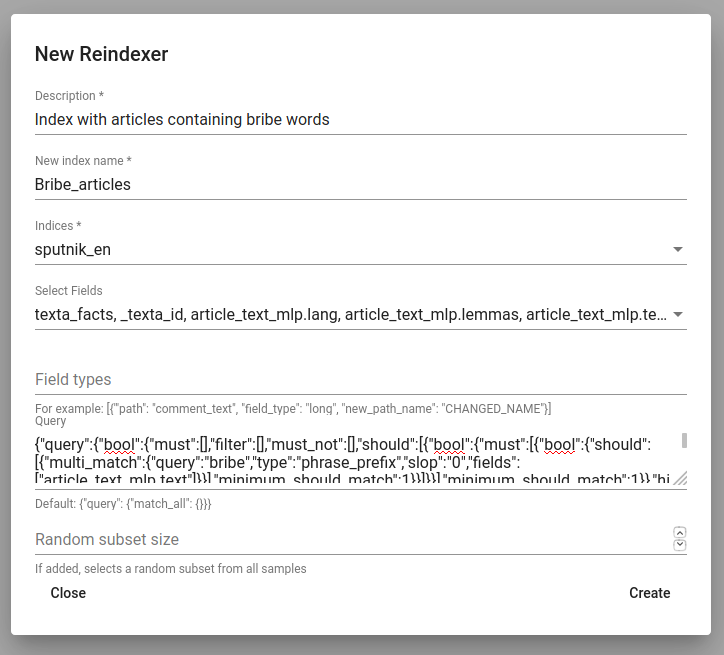
Joonis 20. Uue indeksi loomine¶
Dataset Importer¶
Uusi andmeid saab Toolkit-i üles laadida Tools-i all oleva Dataset Importer-iga. Selleks klõpsa nupul CREATE, mis avab joonisel 21 olevavaate. Seal tuleb kirjeldada andmestikku (Task description), anda sellele nimi (Dataset name) ning valida, millist faili üles laaditakse (arvutist saab sobiva faili valida, kasutades kausta-kujulist nuppu). .csv formaadis faili üles laadides tuleb valida ka eraldaja (tavaliselt koma). Dataset importer toetab ka json ja excel failide üles laadimist. Seejärel vajuta Create. Faili üleslaadimise protsessi ning metaandmestiku näeb sealsamas Dataset Importeri all. Üles laaditud andmestiku saab kustutada Actions all oleva kolme täpikese abil.
Nüüd on võimalik neid andmeid kasutada projektides andmetele antud nimega.
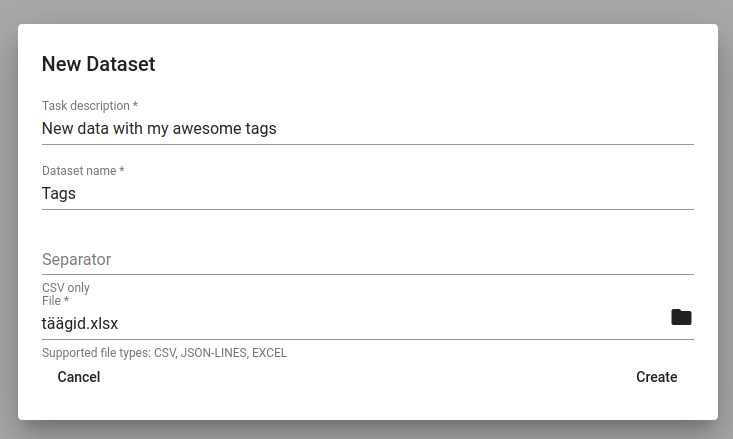
Joonis 21. Uue andmestiku importimine¶